
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- SAP Community Question Analysis (Data Gathering)
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Advisor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
03-07-2022
8:57 PM
Introduction
Since my start within the Product Management team of SAP Data Intelligence, on a regular basis I check together with other colleagues the incoming questions within the SAP community associated to the SAP Data Intelligence product. This incorporates manual work which has the potential to be simplified and furthermore analyzed. During the last months I looked at the unordered questions within the SAP Community and I came up with the following idea: Can we associate topics to each question to determine in which topic area a question came up to then drive on these results analysis which topic are currently discussed within the SAP Community.
As the project covered multiple parts, I decided to split the project into multiple blog posts for the respective sub areas the project covered. As this is not a typical blog post where I show certain functionalities in detail but rather a realization of a use case, I am open for every feedback and suggestion regarding possible improvements.
This first blog post will cover the data gathering and pipeline approach for the use case.
Background
Right at the beginning of the project I discovered that robert.russell2 conducted an analysis on the SAP Community and used an API that was mainly based on the SAP Search API.
To get a better understanding what data can be extracted from the SAP Community, here is an overview how a question within the SAP community is structured:

Overview of SAP community question structure
- Name of user
- Last update of question
- Title of question
- Content of question
- Assigned Tags (user defined and predefined tags)
- Similar questions (similar questions to posted question)
To now extract the specific results we are interested in, we will look at the different parameters we use to retrieve our data from the API within the next section.
API Query
To get all questions related to SAP Data Intelligence we will use the following parameters to prefilter our results.
- Page (page number to be returned – used to dynamically get the right pagination)
- Limit (maximum number of items to be returned)
- orderBy (Ordering mechanism for questions)
- order (Sord Order dependent on the ordering mechanism of orderBy)
- contentTypes (Selection of content types present in the SAP community)
- managedTags (Managed Tags that are assigned to a content type)
- updatedFrom (defines updated question date starting point, Format: yyyy-MM-dd HH:mm:ss)
- updatedTo (defines updated question date ending point, Format: yyyy-MM-dd HH:mm:ss)
Regarding the questions from the community, we are not only interested in the questions in the past but also in the future changes that might happen to the question. Some changes can include an updated question content, a change in the title or newly added answers to a question.
As the idea is to run the query every day, I decided to run for the first time a so-called initial load to retrieve all questions and afterward only those questions that received a change on the same day. Based on these regulations the first run has no defined updatedFrom and updatedTo parameters. The following runs include both parameters and set it to midnight of the day for updatedFrom (e.g. 2021-01-01 00:00:00) and one second before midnight of the same day for updatedTo (e.g. 2021-01-01 23:59:59).
The remaining listed parameters will not change over the course of the different query runs of the API and will therefore not change. As we want to get all the questions that are related to the tag SAP Data Intelligence, we will use the following parameters:
- Page: dynamically defined
- Limit: 1000
- orderBy: UPDATE_TIME
- order: DESC
- contentTypes: question
- managedTags: 73555000100800000791
- updatedFrom: yyyy-MM-dd 00:00:00
- updatedTo: yyyy-MM-dd 23:59:59
As the API returns on the one hand data we don’t need, on the other hand also misses some information, I will present aspects of the returned API content.
API content
After we submit the query defined in the previous section to the API, we receive a json with the following structure:
{
"query": {
Page: 0,
Limit: 1000,
…
},
"totalCount": 441,
"contentItems": [
{
"url": "https://answers.sap.com/questions/x/title.html",
"title": "Title",
"excerpt": null,
…
},
…
],
}
The questions we want to store within our model can be found under the json key contentItems, which stores the questions in an array. Each individual question has the different attributes stored in a JSON. A detailed definition of the resulting schema can be found under the documentation of the API. For the questions we extract the following information from the JSON:
- URL (Url of the questions without the prefix https://)
- Title (Title of the question)
- Created (Datetime in ISO for creation of question)
- Updated (Datetime in ISO for last update to question)
- managedTags (List of jsons with associated tags)
- guid (ID associated to one tag)
- displayName (Name associated to one tag)
- answerCount (count of answers under question)
- commentCount (count of comments under question)
- language (Language of question)
To update the question and to assign topics to each question, I needed to add different properties to the data of the questions. By comparing the present attributes with the needed attributes, it became obvious that the API does not provide all necessary attributes. Therefore, the following section will outline the missing attributes we need to gather outside of the API.
Missing query attributes
To fully be able to capture all information from the SAP Community Web page we must generate and retrieve additional information that are not provided by the API.
The first requirement to fulfill is the possibility of updating items that have changed in the past. As we want to have data stored in a database, we would like to have a unique ID from which we then perform an Update on the changed entry. As theoretically none of the extracted fields from the json is unique, I decided to combine the Title and the Created Date of a question into a concatenated string. As currently there is no limitation in the length of the title which could exceed a possible limit in a database, I decided to hash the string by using the SHA256 algorithm which returns a hexadecimal string with always a length of 64.
The second necessary attribute that needs to be added is the topic categorization of a question. And here comes the tricky part with no straightforward solution. Before diving into the solution, I will shortly explain how I extracted the content of a question. We therefore differentiate between the Authors of answers we are interested in for the e-mail automation and the question content necessary for the keyword and topic extraction.
In the next section the methodology for the author extraction for the answers is presented.
Extract Author of answers
For one part of the project, the e-mail automation, it is necessary to have an overview which set of persons have answered the collected questions, I will shortly go over the coding I have done to solve collect all the author names of answers previously specified. As we are only interested in those authors that agree to participate in the automatic e-mail reception, we only store those names associated with the question.
As the website is loading the answers to the questions dynamically, we need to parse the authornames from the JavaScript part of the website. The valid names are stored in the list validAuthorNames. In the following you can see the code snippet necessary to extract the names of answer author.
validAuthorNames = set([‘test.name1’, ' test.name2', ' test.name3', ' test.name4'])
def extractQuestionAnswer(inputUrl):
page = requests.get(inputUrl)
soup = BeautifulSoup(page.content, "html.parser")
content = soup.find_all('script')[5]
# extract answer authors from script tag
authorString = re.findall(r'(\\"author\\":\{\\"username\\":\\"[\w.]+\\")', str(content))
jsonStringList = ['{' + element.replace('\\', '') + '}}' for element in authorString]
jsonAuthorList = [json.loads(element).get('author').get('username') for element in jsonStringList]
return list(set(jsonAuthorList))
questionAnswerAuthorId = extractQuestionContent(questionUrl)
questionAnswerAuthorId = [author for author in questionAnswerAuthorId if author in validAuthorNames]
Question Content
As already stated, the topic modelling is based on the content a user has written in the question. As unfortunately the API does not return the content of the question, I needed to build a little helper function to extract the content of the question.
The method is written in Python and makes use of the packages request and BeautifulSoup.
The input of the method is the URL of the question and the html class we want to extract from the website. The html class that stores the content of a question is named ds-question__content and wraps the whole question content into one html class.
In the first step of the method, I use the get command of the requests library to retrieve the html page content and store it into the variable page. To be able to parse the content accordingly I use the BeautifulSoup library and respective method to parse the content of the response into an html like structure and store it in the variable soup.
To extract the relevant class, we use the find command of the BeautifulSoup library and set the parameter class_ to the respective class we used as an input for the content. The text then gets extracted and all new lines abbreviations get replaced with a whitespace.
As for data intelligence there are many acronyms, I defined a list of known acronyms and replaced them with the word di with the help of the sub command of the re package.
After the content was extracted, the method returns question content stored in the variable content.
Below you can see the script of the described methodology for the content extraction.
def extractQuestionContent(inputUrl, inputContentType):
'''
By input the URL and the Content Type the method extracts the respective
content from the given URL. Variable inputContentType is a respective html
class that needs to be present on the searched page
'''
page = requests.get(inputUrl)
soup = BeautifulSoup(page.content, "html.parser")
if inputContentType == 'ds-question__content':
content = soup.find(class_=inputContentType).text.replace("\n", " ")
content = content.lower()
content = re.sub(r'\bdi\b|\bsap di\b|\bdata intelligence\b|\bsap data intelligence\b|\bdata hub\b|\bsap data hub\b|\bdh\b|\bsap dh\b|\bdatahub\b|\bsap datahub\b', 'di', content)
return content
Topic creation
For the topic creation there is the present area of topic modelling. During the project, I investigated different approaches for topic modelling. Unfortunately, the different topic modelling algorithms weren’t giving satisfactory results. Therefore, I chose to establish my own simple topic creation approach for the project. In the following paragraphs the procedure is outlined.
Given the content of a question I assumed that a set of the most important keywords of a text build the topic of a question. As the base for our topic creation is a keyword extraction, I selected an already existing python package to create the keywords called Keybert. Keybert makes use of the famous Transformer Models, a special subcategory of neural networks and is therefore able to catch semantic aspect of a question content for the keyword extraction. To get an overview of the procedure of the keyword extraction, I will outline a short overview of the technical procedure of the package:
- The question content is embedded into a vector using a transformer model to represent semantic aspect of the document
- Keywords are extracted as n-grams from the document using Bag Of Words technique(tf-idf vectorizer)
- Each extracted keyword is then transformed into a vector by using the same model as for the question content embedding
- The keyword and document embedding are then used to calculate the cosine similarity. N keywords with the highest cosine similarity are the used as the keywords
For the model of the embedding, I used in the project the default model given by the package, which is the all-MiniLM-L6-v2 model from sentence-transformers. The package returns the five most similar keywords compared to the document embedding. Keybert also provides the possibility to define the n-gram range of keywords. For those not familiar with the word n-gram, here is a short overview what n-grams are.

Example of n-grams
In my project I use uni- and bigrams as valid n-gram options for the keywords. Furthermore, I set the possible stop words to English words, so that words like and, we, to, etc. are not considered as valid keywords.
In the following you see the few lines of python code to extract the keywords and store them in a list. As we are only interested in the keywords, I extract the first element of the returned tuple and store it in a list called keywordsContent by using a list comprehension.
kwModel = KeyBERT()
keywordsContent = kwModel.extract_keywords(questionContent, keyphrase_ngram_range=(1, 2), stop_words='english')
keywordsContent = [key[0] for key in keywordsContent]
Before we jump into the overview on how to productize the use case, I will present in the next section a short overview of the data tables that will be necessary for the following blogposts in the blog post series.
Table design
To be able to use the community in different occasions I decided to write four different tables that are connected via the QuestionId Field within the table.
The following structures give an overview of the created tables:
Questiondata:
| Name | Data Type | Key |
| Questionid | CHAR(64) | X |
| Title | CHAR(5000) | |
| URL | CHAR(2000) | |
| CREATEDDATE | DATE | |
| UPDATEDDATE | DATE | |
| ANSWERED | CHAR(3) | |
| COMMENTCOUNT | INTEGER | |
| ANSWERCOUNT | INTEGER |
Questionkeyword
| Name | Data Type | Key |
| Questionid | CHAR(64) | X |
| CREATEDDATE | DATE | |
| Keyword | CHAR(5000) | X |
Questiontag
| Name | Data Type | Key |
| Questionid | CHAR(64) | X |
| CREATEDDATE | DATE | |
| Tag | CHAR(5000) | X |
Questionanswerauthor
| Name | Data Type | Key |
| Questionid | CHAR(64) | X |
| CREATEDDATE | DATE | |
| AnswerAuthor | CHAR(5000) | X |
Productization
For the productization I use SAP Data Intelligence as a product of choice. As already mentioned, the solution and coding might differ from using a local approach.
As I selected Data Intelligence as the productization platform to move forward the main tool for the productization is the pipeline modeler. For the starting point of our pipeline, we need to gather the data and bring it into the format as discussed in the previous paragraph.
For the API Call I already discussed and showed in the sections API query and API content the necessary parts for the procedure of extracting the results from the API. How to get the necessary attributes will be discussed in the next section.
An overview of the pipeline is displayed in the following image.
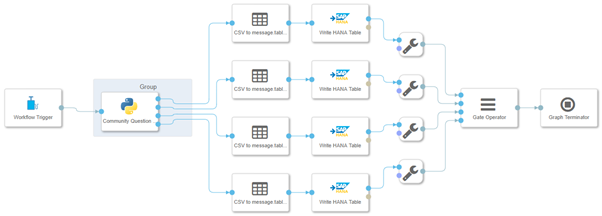
Data Intelligence Pipeline of Web Scraper
Community Question Scraper
The community question scraper is a python-based operator that extracts data from the API with enriching the data from the presented web scraping possibility. All the other entries get extracted from the resulting json with the get command in python. I will not go into too much detail of the whole routine for extracting every single variable as a lot of the steps are repetitive.
For each question all the variables are stored in each iteration into a dictionary which then gets transformed into a pandas dataframe after all questions are processed.
questiondf = pd.DataFrame.from_dict(questionDict, orient='index')To get the table in the format as we defined it in the section table design, we need to split and wrangle our base table and get them into the format that is specified in the section Table design. In the next section the transformation from the Python output in format of an csv to the appropriate structure of type message.table is outlined.
Csv to message.table operator
After we transformed the four different outputs of each table, we need to transform the output from the scrape operator to the format of message.table as we want to use the Write HANA Table Operator.
To transform the output in the format, we first read in the content of the CSV to get a pandas dataframe. The reason behind this is to check whether our columns are of type object/ integer or if a datetime variable is present. Therefore, we iterate over the columns and try to transform the column into a datetime data type. If the transformation is valid, the column datatype gets changed. If it is not successful and throws an error, the column will be skipped, and the datatype will not be changed. The following script outlines the conversion from csv to the expected JSON structure from the Write HANA Table operator.
from io import StringIO
def on_input(data):
data = StringIO(data.body)
df = pd.read_csv(data)
for col in df.columns:
if df[col].dtype == 'object':
try:
df[col] = pd.to_datetime(df[col])
except ValueError:
pass
columns = [{"name": name, "class": "timestamp"} if df[name].dtype == 'datetime64[ns]' else {"name": name} for name in df.columns]
content = df.values.tolist()
tableMessage = {
"Attributes": {
"table": {
"version": 1,
"columns": columns
}
},
"Encoding": "table",
"Body": content
}
api.send('output', tableMessage)
api.set_port_callback('input', on_input)
Write HANA Table operator
To write the data extracted from the website and API to a HANA database I use the Write HANA Table operator. The Write HANA Table operator can be connected to a specified connection in the connection management of SAP Data Intelligence. I selected a static configuration mode so that I need to specify the tables manually as also the statement to insert the data to the HANA data table. The user has the possibility to select either INSERT or UPSERT, which is a combination of an update and insert. As we also want to update the records, we are using the UPSERT statement.
In the next section we define the operator that prevents the operator too early before writing all data to the data table.
Conclusion
This blogpost showcased the data gathering and storing of the data retrieved from the SAP Community related to the questions. With SAP Data Intelligence and the pipeline modeler we have the possibility to merge data from APIs together with unstructured data from the Web and store it in a database. In the second blogpost of the blog post series, we explore the possibility to automate an e-mail procedure that forwards open questions to the appropriate author. The second part of the blog post series covers the e-mail automation of open questions. The third part of the blog post series examines how the questions can be clustered how to integrate our results in an SAC Dashboard.
Acknowledgements
This blogpost and the related use case wouldn’t have been possible without the continuous support of my colleagues. A special thanks needs to go out to britta.jochum, sarah.detzler, daniel.ingenhaag and yannick_schaper for their continuous support during the project and the preparation for this blog post.
- SAP Managed Tags:
- SAP Data Intelligence,
- API,
- Python
Labels:
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
110 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
74 -
Expert
1 -
Expert Insights
177 -
Expert Insights
348 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
GraphQL
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
14 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,575 -
Product Updates
392 -
Replication Flow
1 -
REST API
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,871 -
Technology Updates
482 -
Workload Fluctuations
1
Related Content
- Deep dive: End-to-End processes with a closer look on Source to Pay in Technology Blogs by SAP
- Process Insights discovery edition - monetary value? in Technology Q&A
- SAC Live Connection Dynamic Text Date/Time - Date not showing correctly in Technology Q&A
- SAP Integration Suite - Design Guidelines in the integration flow editor of SAP Cloud Integration in Technology Blogs by SAP
- SAP Datasphere catalog - Harvesting from SAP Datasphere, SAP BW bridge in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 15 | |
| 11 | |
| 10 | |
| 9 | |
| 8 | |
| 8 | |
| 7 | |
| 7 | |
| 7 | |
| 7 |