
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Replication Flow Blog Series Part 4 - Sizing
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Product and Topic Expert
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
12-15-2023
8:17 AM
This blog is part of a blog series from SAP Datasphere product management with the focus on the Replication Flow capabilities in SAP Datasphere:
Replication Flow Blog Series Part 1 – Overview | SAP Blogs
Replication Flow Blog Series Part 2 – Premium Outbound Integration | SAP Blogs
Replication Flows Blog Series Part 3 – Integration with Kafka
Data Integration is an essential topic in a Business Data Fabric like SAP Datasphere. Replication Flow is the cornerstone to fuel SAP Datasphere with data, especially from SAP ABAP sources. There is also a big need to move enriched data from SAP Datasphere into external environments to succeed certain use cases.
Topics I will be focusing on in this blog:
- Overview of Replication Flow use cases & configuration of your SAP Datasphere tenant
- Explaining the terminology & sizing concept when using Replication Flows
- Sample sizing calculation for a given scenario using Replication Flows
- Topics to be considered when modelling a Replication Flow & sample scenarios based on certain changes executed by a user
- Conclusion
Overview of Replication Flow use cases & configuration of your SAP Datasphere tenant
Please find below an overview of the required sizing aspects for three major use case scenarios. In this blog we concentrate on the “Replication Flow” part and will not go into the details of using and sizing considerations for Transformation Flows, where Transformation Flows are technically running on Datasphere’s underlying HANA compute resources.

* Planned for Datasphere local tables with delta capture (see roadmap explorer for latest news)
Use Case 1 – Inbound Data Movement:
Replication Flows will be used to perform inbound data replication from various different source systems that a Replication Flow supports (e.g. SAP S/4HANA, SAP ECC, SAP HANA etc.) into SAP Datasphere local tables as target. Here you can choose to either load the data into “traditional” SAP Datasphere local tables or local tables with delta capture (= delta capture is switched on by default in case you use load type initial + delta in your Replication Flow).
Use Case 2 - Outbound Data Movement:
In the second use case, we take a look on the situation where data is already available in SAP Datasphere (e.g. in local tables) and should be further distributed into other target systems including SAP as well as non-SAP target systems. The data could for example be made available by other tools, e.g. transformed data of Transformation Flow or other data that is available in form of local tables within a Datasphere space.
At the moment only Datasphere local tables are supported using initial load capabilities, additional enhancements are planned and please keep an eye on the roadmap explorer of SAP Datasphere for any news.
Use Case 3 – Pass-Through Option:
In the third use case, Replication Flows replicate the data directly from a specified source system into a defined target system (other than SAP Datasphere) without persisting any data in SAP Datasphere, i.e. the data is passed through Datasphere without storing the data inside SAP datasphere. Sample scenarios are:
- Replicate data from SAP S/4HANA Cloud to Google BigQuery
- Replicate data from SAP ECC to SAP HANA Cloud
- Replicate data from SAP S/4HANA on-Prem to HANA Data Lake Files or 3rd party object store
Later, we will also map the required sizing aspects to each use case to illustrate which aspects need to be considered for each of the three use cases described above.
In the next chapter, we will explain some of the important terminology within the Replication Flow area, which we need as a baseline to understand the sizing aspects in this blog.
Explaining the terminology & sizing concept when using Replication Flows
Definition: Replication Flows make use of so-called Replication Flow Jobs running in background to replicate data from a defined source to a defined target system. Each Replication Flow Job includes several replication threads that are responsible for transferring the data during initial & delta load phase between the source and target system. A Replication Flow can have a certain number of replication threads assigned by a user to allow users to influence the performance throughput of the replication, especially when replicating large volumes of data.
There is a certain amount of default replication threads which are assigned to a Replication Flow and a maximum number of parallel threads that a user can assign to a Replication Flow to influence the performance throughput during the initial load process.
Please find below a list of terminologies including a brief explanation and description of each component:
| Term | Definition & description |
| Replication Flow | Represents the user-facing component in the SAP Datasphere through which a user can model & monitor the data replication using the Data Builder UI for creation as well as the Data Integration monitor application for monitoring Replication Flows. |
Replication object | Replication objects are the source data sets a user is selecting in the defined source system that need to be replicated into the defined target system. Replication objects could be for example CDS Views from SAP S/4HANA or tables from an SAP Business Suite (SAP ECC) as well as tables from SAP HANA Cloud. Users can add multiple replication objects to a Replication Flow with a maximum of 500 replication objects that can be assigned per Replication Flow. |
| Replication Flow Job | Represents the technical runtime artefact, which is running in background artefact responsible for replicating the data from the source to the target system. In SAP Data Intelligence Cloud, a Replication Flow Job is also known as “worker graph”. One Replication Flow Job consists of 5 replication threads through which data can be replicated during initial and delta load phase with an overall maximum of 10 Replication Flow Jobs that can run in parallel per Datasphere tenant. Per default, 2 Replication Flow Jobs are assigned for each Replication Flow that is being derived from the assigned replication threads. Replication Flow Job is the same artefact mentioned as “max. parallel jobs” in the tenant configuration described here in the Data Integration section. |
| Replication threads (initial load) | Are the threads that are responsible for transferring the data during the initial load phase from the source to the target system with one or multiple threads running in parallel. In total there cannot run more than a maximum of 50 replication threads in parallel per SAP Datasphere tenant. One Replication Flow Job (= RF Job) has in general 5 replication threads through which data can be replicated. Per default, 10 replication threads ( 10 = 2 RF Jobs * 5 threads) are assigned to each Replication flow that a user is creating in SAP Datasphere UI, which can be changed by a user when creating a Replication Flow (link). |
| Replication threads (delta load) | Number of threads transferring the data during the delta load phase, where one replication object can currently only use one delta thread at a time (except CDS and SLT case) and is linked to overall total maximum number of replication threads per Datasphere tenant. Per default 1 thread is assigned per replication object during the delta load phase. |
Important Note: Based on the information above you may wonder what happens if a user allocates more replication threads across multiple Replication Flows, which exceeds the current maximum number that can be configured per tenant (= 50 replication threads) or if more than 50 replication threads are replicated in parallel in the delta load phase. Later on, we will also illustrate some example scenarios in case a user is performing certain changes including the impact it will have. Please check the information in chapter "User actions and impact on Replication Flow sizing as well as running Replication Flows" for more information.
The following diagram illustrates the relationship between the Replication Flow components a user can select & configure in the SAP Datasphere UI within the Data Builder application and the underlying technical run-time artefacts (= Replication Flow Job). The visualization of the technical Replication Flow Job is only for demonstration purposes and user will not be able to see it in the SAP Datasphere system, but only interacts with the Replication Flow user interface embedded in SAP Datasphere data builder and data integration monitor applications.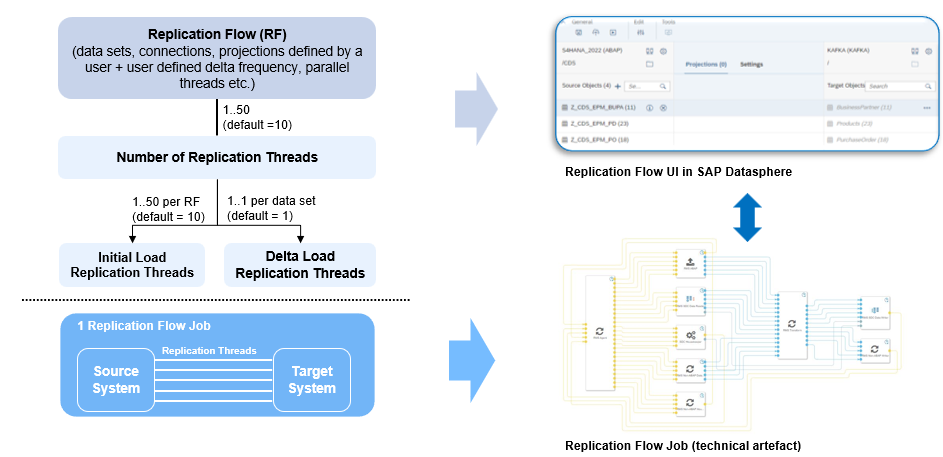
Now we take a look on the terminologies being used in the context of sizing Replication Flows in your SAP Datasphere tenant. These terms can be derived from the SAP Datasphere Estimator as well as the SAP Datasphere tenant configuration documentation.
| Term | Definition & description |
| Data integration (blocks) | The data integration tile in the SAP Datasphere Estimator covers the usage of Replication Flows and allows to configure certain amount of data integration blocks in order to use Replication Flows for data replication scenarios in the Datasphere tenant. Please note that other artefacts such as Data Flows etc. are not covered in this concept, but only the Replication Flows! |
| Execution (Node) Hours | Is the unit of consuming Replication Flows and is calculated based on the memory usage in GB of a Replication Flow over a period of time. The number of node hours available for Data Integration applications per month is calculated based on the number of allocated data integration blocks. Per one additional data integration block, you will get one additional node hour for your SAP Datasphere tenant. The consumption of node hours is always relevant whenever Replication Flows are being executed in your SAP Datasphere tenant and each tenant can consume up to 200 node hours for free. |
Max. Parallel jobs | Defines the degree of parallelization via assigned replication threads to be used for replicating the data and is referring to the number of Replication Flow Jobs that we described earlier. The maximum number of parallel jobs is derived from the number of data integration blocks assigned. For every 100 execution hours assigned via 100 data integration blocks, you will get one extra parallel job up to an overall maximum of 10 Replication Flow Jobs per Datasphere tenant. The default & minimum number of parallel jobs is 2 per SAP Datasphere tenant. |
Premium Outbound (blocks) | In case you are using Replication Flows to load data into non-SAP target systems, you also need to configure a certain amount of premium outbound blocks on top of the data integration blocks. The premium outbound configuration is based on the replicated data volume, and you can assign blocks in the size of 20 GB (data volume) per block to your SAP Datasphere tenant. |
In a next step, we will map the two different components in the SAP Datasphere tenant configuration (“Data Integration” & “Premium Outbound Integration”) to the Replication Flow use cases we have mentioned earlier in this blog:

Use Case 1 - Inbound Data Movement
In the first use case, the component “Execution (Node) Hours” need to be considered when performing inbound data movement from various source systems into SAP Datasphere as target using Replication Flows.
Use Case 2 – Outbound Data Movement
In the second use case, the users need to configure “Execution (Node) Hours” when replicating data out of Datasphere as general requirement to use Replication Flows in each scenario. In case user is planning to move data to non-SAP target systems (e.g. Kafka, BigQuery, 3rd party object store etc.), premium outbound integration needs to be configured on top as an additional configuration for the SAP Datasphere tenant. If the data is being replicated to SAP target systems, like SAP HANA Cloud or SAP HANA Data Lake Files, premium outbound integration is not required.
Use Case 3 – Pass-Through Option
In the third use case, the users need to configure “Execution (Node) Hours” as well for the usage of Replication Flows in general similar to use case 1 and 2. Additionally, if the configured target system in a Replication Flow is a non-SAP target, users need to configure premium outbound integration on top based on the required data volume that will be loaded to a non-SAP target system. If the data is being replicated to SAP target systems, like SAP HANA Cloud or SAP HANA Data Lake Files, premium outbound integration is not required similar to use case 2.
Important information about the performance measurement in this blog
Before we go into the sample sizing calculation, there is one important point that we want to describe upfront, which is the performance measurement that is being used for the sample calculation in this blog.
Based on certain tests, we found out that the measure “cells” (cells = rows * columns) seems to be a good indicator for measuring performance, which is more precise compared to record-based performance calculations. The reason for this is that there are several source data artefacts with various amounts of columns, e.g. CDS View based on ACDOCA having 400 columns up to small CDS Views having only 50 columns, where the number of columns is heavily influencing the overall performance of records that can be replicated in a certain amount of time, e.g. number of records replicated per hour. Therefore, we will perform our sample calculation based on the measure “cells”, which is considering the number of columns per data set and thus reducing the risk of having huge variations between different data sets.
Simple example for calculating the number of cells for a particular data set:
CDS View A in SAP S/4HANA having 10 million records * 50 columns = 500 million cells
CDS View B in SAP S/4HANA having 10 million records * 350 columns = 3.500 million cells
Here you can already see that the total number of cells is deviating based on the number of columns & rows a specific CDS View has and the reason why we have decided to follow the cell-based calculation instead of using only record-based calculation.
Sample sizing calculation for a given scenario using Replication Flows
In the following paragraph, we will take a look into a concrete sample scenario to load data in form of CDS Views from an SAP S/4HANA system into SAP Datasphere, where we want to calculate the required amount of data integration blocks during the initial load as well as the delta load phase. Due to the complexity of such a calculation, we have made the calculation based on certain assumptions to simplify the calculation and illustrate the required steps.
Scenario description:
We have a user that wants to replicate data from 20 CDS Views having an overall initial volume of 600 mio records from SAP S/4HANA on-Premise into SAP Datasphere delta local tables as target system. Here we assume that the 20 CDS Views have an average number of 150 columns and the user wants to achieve a desired performance throughput of 60 mio rec. / h for the initial load that is valid for all 20 CDS Views.

For the delta load phase, we assume that there is an overall change volume for 10 mio. records / h for all 20 CDS Views to load in real-time*.
* Please note that near real-time delta replication for Replication Flows is not yet available as public feature in SAP Datasphere, but will come in early 2024 (check the roadmap explorer for any updates)
Before we now go into the detailed sizing activities, we also want to highlight certain assumptions we have specified for our sizing exercise to reduce complexity and provide a simplify way to perform a sizing calculation.
Important Note: With the sizing exercise & numbers in this blog we want to provide at least some guidance on rough sizing figures for a given scenario, but those might not fit 1:1 for every real-life scenario due too many variations in infrastructure landscapes that can exist in individual enterprises.
Assumptions:
- We are not considering any infrastructure or network related configurations in this sample sizing exercise.
- Instead of calculating the amount of cells to be replicated individually for each CDS View, we will calculate the amount of cells based on average number of columns for all CDS Views (= 150 columns on average).
- We assume an average performance of 520 mio. cells / h per replication thread during the initial load phasePlease note that we take this number as a current average, but we want to provide some additional throughput figures at a later point for specific scenarios using different source and target system combinations (e.g. SAP S/4HANA to object stores or SAP Business Suite to Google BigQuery etc.). Assuming that a cell may have an average size of 10 bytes, this results in roughly 4,8 Gigabyte (GB) throughput per replication thread.
- We assume an average performance of 260 mio. cells / h per replication thread during the delta load phaseReason: Whereas in general the throughput during the delta load phase can replicate up to a max. of 520 mio. cells / h similar to the initial load, there is usually no continuous replication of the same volume during the delta load phase compared to the initial load phase. Experience showed that this is roughly half the volume of the initial load, but of course this can deviate depending on the individual scenario and system landscape.
- As stated before, there is currently a limit of max. 10 Replication Flow Jobs per Datasphere tenant, which is planned to be enhanced in future. For planned enhancements & news, please check the SAP Datasphere roadmap explorer.
In the table below, we want to provide a high-level overview via “quick sizer” based on the performance assumptions we provided above and illustrate the achievable throughput for three different configurations using the Number of max. parallel jobs (= Replication Flow Jobs):

* based on the average throughput is 520 million cells / hour per initial load replication thread
In the first example using 1 RF job: 520 mio cells / h * 10 replication threads = 5.200 mio cells / h
** based on the average throughput of 260 mio cells / hour per delta replication thread
In the first example using 1 RF job: 260 mio cells / h * 10 replication threads = 2.600 mio cells / h
*** Planned to be enhanced in future, please check roadmap explorer for updates
Now we go into the details using a three-step approach to find out how you need to size your SAP Datasphere tenant for our given example scenario:
- Calculate amount of data to be replicated considering the desired performance throughput
- Calculate number of required jobs required to replicate the initial data based on desired throughput by customer
- Calculate required sizing for real-time* data replication during the delta load phase based on Node Hours
* Please note that real-time delta replication for Replication Flows is not yet available as public feature in SAP Datasphere, but will come in early 2024 (check the roadmap explorer for any updates).
Calculate amount of data to be replicated considering the desired performance throughput
First, we convert the figures from the scenario (record-based numbers) into the metric of “cells”. Here we now take the average number of columns, but in real-life you could of course get the concrete numbers by multiplying the figures per CDS View. Here we simplify it by just calculating the overall number of records multiplied by the average number of 150 columns among all CDS ViewsTotal amount of data in cells = 600 mio. records * 150 columns = 90.000 mio cells in total
Desired throughput in cells = 60 mio. records * 150 columns = 9.000 mio cells / h
Calculate number of required jobs required to replicate the initial data based on desired throughput by the customer
Second, we now calculate the required number of Replication Flow Jobs based on the desired throughput that has been specified and the performance throughput a single replication thread can handle during the initial load.
9.000 mio cells /h desired throughput ÷ 520 mio cells /h per replication thread = 17,31 = ~ 18 replication threads
Now that we have the required number of replication threads that are needed to achieve the desired performance throughput, we will calculate the required amount of Replication Flow Jobs and the amount of “Execution (Node) hours” for the initial load phase.18 replication threads ÷ 5 threads per Replication Flow Job = 3,5 = ~ 4 Jobs = 400 Node Hours (200h additional + 200h incl. for free)
The 400 Node Hours are being calculated based on the 4 Jobs that are required and as explained before in this blog, for each 100 Data Integration Blocks another parallel job is being available resulting in a need of a total of 400 node hours.
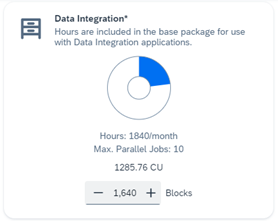
If we now subtract the 200 node hours that every customer gets for free for each SAP Datasphere tenant, it would require to assign 200 data integration blocks to get another 200 node hours for the initial load phase as illustrated in the SAP Datasphere Calculator:

Calculate required sizing for real-time* data replication during the delta load phase based on Node Hours
In this scenario when looking into the real-time replication use case, we assume that each Replication Flow Job is running permanently 24/7 for 30 days per month to replicate the delta records that are produced in the source system = 30 days *24 h = 720 hours (=Node Hours) per job.First, we calculate the amount of delta that needs to be replicated per day based on our scenario description (10 million records / hour) and convert it into the measure of “cells” using again the average number of 150 columns.
Daily delta to be replicated = 10 mio records / h * 24h = 240 mio cells / day * 150 columns = 36.000 mio cells / day total delta
Second, we calculate the maximum throughput that one Replication Flow Job can handle per day based on our performance assumptions before (= 250 mio cells /h per thread).
Daily max. delta throughput = 260 mio cells / h * 24h = 6.240 mio cells / day per thread * 5 threads per job = 31.200 mio cells / day per JobThird, we now calculate how many Replication Flow Jobs & node hours that are required to handle the change volume in our scenario for real-time data replication and round it up to the next full integer value to have some buffer as well as the fact that only full number of Replication Flow Jobs can be configured in your tenant configuration.
Required number of Replication Flow Jobs = 36.000 mio cells ÷ 31.200 mio cells per Job = 1.2 = ~ 2 Replication Flow Jobs * 720h per Job = 1.440 h (= Node Hours)
In the above calculation you can see that we multiply the result of required number of Replication Flow Jobs by the run-time of 720h that we mentioned in beginning of step 3.
Note: If real-time replication is not required, starting in early 2024 users will be able to configure the delta load frequency via the following parameter to let the delta interval run in a certain frequency, e.g. every 1 or 2 hours up to maximum of once per day. With this option, users have the ability to configure delta interval based on their needs, which will then also influence the sizing for the delta load phase and probably consume less node hours compared to the real-time use case.
Configuration of Data Integration Blocks in SAP Datasphere Tenant Configuration (Link)
Now we are taking a look and summarizing both calculated figures for the initial load as well as the real-time delta load phase:
- For using 4 Jobs, the customer needs to at least configure 200 Blocks to realize the initial load
- For replicating 10 mio rec. / h in real-time, the customer needs to configure additional 1440h during the delta load, i.e. additional 1.440 blocks on top
In total the two calculations sum up in the following calculation of:
200 Blocks (initial load) + 1.440 Blocks (delta load) = 1.640 data integration blocks for the first month & 1.440 blocks starting in second month considering the fact that delta volume is the same per month, which will in reality probably look different and may vary from month to month.
Considering Premium Outbound Integration for our sample scenario
If we now think of our previous scenario including a slight adjustment where you want to load data from SAP S/4HANA in real-time directly to a non-SAP target system, e.g. Google BigQuery, then the premium outbound integration (=POI) would need to be configured in addition to the data integration blocks we have calculated before.
Imagine our 20 CDS Views have a volume of around 300 GB initial load data volume and a monthly change data volume of 60 GB, it would end up in:
- Assignment of 15 blocks for initial load
= 15 blocks * 20 GB per block = 300 GB initial load volume
- Assignment of 3 blocks per month for delta load
= 3 blocks * 20 GB per block = 60 GB delta load volume
In total the two calculations sum up in the following calculation you can perform in the SAP Datasphere tenant configuration or the SAP Datasphere capacity unit calculator:
15 blocks (initial load) + 3 blocks (delta load) = 18 blocks for the first month & 3 blocks starting in second month considering the fact that delta volume is the same per month, which will in reality probably look different and may vary from month to month.

Topics to be considered when modelling a Replication Flow & sample scenarios based on certain changes executed by a user
- All replication threads assigned to a Replication Flow will be shared for all replication objects (data sets) that are configured in a Replication Flow.
- Please make sure your SAP ABAP is configured properly and up to date with regards to implementation of required SAP notes. You can check the following two notes for details: https://me.sap.com/notes/2890171 & https://me.sap.com/notes/2596411 !
- There are also certain actions a running Replication Flow cannot handle during run-time for which it would need to be redeployed and re-initialized when running it with initial + delta load type. In future the behaviour should be improved to also allow more flexibility for running Replication Flows to avoid any re-deployment.
- In case you want to add another Replication object to an existing & running RF
--> Alternative solution: Create a new Replication Flow - In case you want to add or change the change the filter, mapping or load type
- In case you want to change or re-name the target data set
- In case you want to change the source or target connection
- In case you want to add another Replication object to an existing & running RF
There exist certain scenarios a running Replication Flow can handle without the need to re-initialize the Replication Flow such as:
- In case you add a non-primary key column in the source, the RF keeps running and the new column will be ignored. If you want to add the data of this new column, re-initialization of the data load is required.
- In case you remove a replication object from an existing & running RF, the remaining replications remain unchanged.
- There is a maximum of 500 replication objects that can be added to a single Replication Flow.
- All replication objects in a Replication Flow share the assigned replication threads that have been configured for the Replication Flow.
- The more replication objects are added to a Replication Flow, the more parallel threads are needed to achieve a desirable throughput depending on the overall data volume that is being transferred.
- For very large data sets (e.g., having > 1 billion records) where you want to achieve a high throughput, you might think of having a dedicated, exclusive Replication Flow to achieve an optimal performance by reserving a certain amount of replication threads. We will soon publish a dedicated blog post around performance tuning!
- In case you define a high number of replication threads across multiple Replication Flows, there will be no more than 10 Replication Flow Jobs started in your Datasphere tenant.
Considerations when loading data out of SAP ABAP based source systems:
- Please make sure your SAP ABAP based source systems are up to-date by applying all relevant SAP Notes to make use of the latest features & avoid running into known and already fixed issues (Link).
- Make sure you allow a certain number of sessions triggered by Replication Flows in your SAP ABAP system or you disable the session parameter check (Link).
User actions and impact on Replication Flow sizing as well as running Replication Flows
In the folloing table we want to illustrate what is the result and impact on the data replication in case a SAP Datasphere user performs a certain action in the Data Builder when creating a new or changing an existing Replication Flow:
| Scenario | Impact & Expected Behaviour |
| User increases default replication threads per Replication Flow > 10 (10 replication threads= default = 2 Replication Flow Jobs each having 5 replication threads) | Please note that you might be limited to a certain number of “max. parallel Jobs” configured for your tenant in FTC and an overall maximum of 10 Replication Flow Jobs that can run in parallel per SAP Datasphere tenant! |
| User increases the delta load frequency < 1h (default) | More Node hours will be consumed due to more frequent delta replication that is running. |
| User creates additional Replication Flows to replicate more data from additional source replication objects | More node hours will be consumed. |
| User stops a running Replication Flow | Node hours for this particular Replication Flow will not be consumed any longer. |
| User pauses a running Replication Flow | node hours for this particular Replication Flow will not be consumed any longer until it will be resumed by a user. |
| User configures more replication threads as the maximum allowed per Datasphere tenant | Data replication will continue running, but will not consume more than a maximum of 10 Replication Flow Jobs running in total per Datasphere tenant. |
| User creates additional Replication Flows & exceeding the limit of their total assigned Data Integration Blocks | Data replication will continue running, but will result in higher amount of costs due to higher node hour consumption. For subscription-based customers a contract adjustment needs to be made in case of recurring “over consumption”. |
Conclusion
The information in this blog should hopefully help you to get a better understanding of how you need to size your SAP Datasphere tenant when using Replication Flows based on a sample calculation. Please remember that the figures we illustrated are sample figures that might not be 1:1 the same in your infrastructure and should be seen as an example to calculate the required amount of data integration blocks as well as premium outbound integration depending on your individual use case scenario.
Thanks to tobias.koebler & martin.boeckling and the rest of the SAP Datasphere product & development team who helped in the creation of this blog .
Now that’s it. Thank you very much for reading this blog and please feel free to provide feedback or questions into the comment section!
Important links & resources:
Creating a Replication Flow in SAP Datasphere
Important considerations for Replication Flows in SAP Datasphere
Configure your SAP Datasphere tenant
SAP Datasphere Calculator / Estimator
Information about connecting SAP ABAP sources as source to Replication Flows
Prepare your SAP ABAP based source system for using Replication Flows
- SAP Managed Tags:
- SAP Datasphere
Labels:
4 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
93 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
67 -
Expert
1 -
Expert Insights
177 -
Expert Insights
301 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
GraphQL
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
346 -
Replication Flow
1 -
REST API
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
429 -
Workload Fluctuations
1
Related Content
- Exploring Integration Options in SAP Datasphere with the focus on using SAP extractors - Part II in Technology Blogs by SAP
- 10+ ways to reshape your SAP landscape with SAP Business Technology Platform – Blog 4 in Technology Blogs by SAP
- Explore Business Continuity Options for SAP workload using AWS Elastic DisasterRecoveryService (DRS) in Technology Blogs by Members
- Dynamic Derivations using BADI in SAP MDG in Technology Blogs by Members
- Pilot: SAP Datasphere Fundamentals in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 34 | |
| 17 | |
| 15 | |
| 14 | |
| 11 | |
| 9 | |
| 8 | |
| 8 | |
| 8 | |
| 7 |