
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Exploring the potential of GPT in SAP ecosystem
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Product and Topic Expert
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
06-20-2023
10:25 AM
These blog post series are part of a series of technical enablement sessions on SAP BTP for Industries.Check the full calendar here to watch the recordings of past sessions and register for the upcoming ones! The replay of this session available here.
Authors: yatsea.li, amagnani, edward.neveux, jacobtan
Disclaimer: SAP notes that posts about potential uses of generative AI and large language models are merely the individual poster's ideas and opinions, and do not represent SAP's official position or future development roadmap. SAP has no legal obligation or other commitment to pursue any course of business, or develop or release any functionality, mentioned in any post or related content on this website.
In addition, we are not in any position to give you any legal or commercial advice etc. about LLM providers, such as Azure OpenAI Service or OpenAI Service, which you should get in touch LLM providers directly. The source code of the sample solutions used in this blog post series are delivered as an SAP example under Apache 2.0 license with AS-IS manner. No SAP support available.
Large Language Models (LLMs) like ChatGPT and GPT-4 have gained significant popularity with emergent capabilities. In this fourth session of the series, we’ll explore the potentials of GPT in SAP ecosystem, and discuss how SAP partners can leverage this powerful AI technology in combination with SAP technologies to accelerate their solution development processes, and create more intelligent solutions on SAP Business Technology Platform (SAP BTP).
Here list the full blog post series of Exploring the potential of GPT in SAP ecosystem.
In this blog post, we will start with an introduction to GPT and LLMs, discussing what they are, their potentials and limitations. Then, we will present the storyline of a retailer selling small house appliances, who wants to improve their multichannel customer service by building an intelligent ticketing service on SAP BTP. We will use this example to showcase two ways GPT can help in the implementation: first, we will see how to use GPT as a code assistant for an application in SAP CAP or RAP; secondly, we will see how to integrate GPT APIs in a CAP application.
We hope that by the end of this blog, you will have a better understanding of LLMs and how you can leverage their potential in your BTP solution.
Given the huge attention ChatGPT raised, there are chances you have already at least heard something about it, or maybe even played with it. Let’s take however a few moments to understand what it is.
Quoting Wikipedia.org:
“ChatGPT is an AI chatbot developed by OpenAI. The "GPT" stands for generative pre-trained transformer—a type of large language model (LLM). It is based on OpenAI's GPT-3.5 and GPT-4 foundational GPT models, and has been fine-tuned [..] for conversational applications.”
So, at the heart of the technology are OpenAI foundational models, such as GPT-3.5 and GPT-4. ChatGPT is a chat bot built on top of these, that has been released and made available for anyone to use back in November 2022. This brought the latest trends and techniques in the AI research world to the attention of the public at large, so that now we are constantly hearing about all the technical words highlighted in the definition above. Let’s try to explain what they mean.
The key enabling technology is the transformer architecture. Transformers are a specific example of sequence-to-sequence models, that is to say, deep learning models that ingest a sequence of certain kinds of items (such as words if we are dealing with text, pixels if we are dealing with images, etc. ) and outputs a sequence as well, not necessarily of the same kind. For a simple example, think of a model that can translate a sentence from French to English.
Originally, these kinds of tasks were performed by architectures such as Recurrent Neural Network (RNNs) or Long Short-Term Memory (LSTM), that had some bottlenecks: first, they were not behaving well with large sequences, and second, they were not able to really understand and grab the context of sequences.
The scenario changed completely with the invention of transformers. Thanks to a technique called self-attention, these architectures were able to achieve better understanding of sequences and relationships between items of a sequence. Moreover, they could handle large sequences better, and they could be easily parallelizable for GPU computing. GPT models are not the only examples of transformers: for instance, if you type any question in the Google search bar, you will get an answer powered by BERT, the state-of-art technology back in 2018.
The various transformer architectures proposed over the years have been growing larger and larger in size, until with GPT-4 we reached about 1 trillions parameters, requiring various terabytes to be stored. With the growing size, the technology started to show unprecedented sequence understanding capabilities, and the opportunity of retaining an impressive amount of information learnt from training the large knowledge bases.
Consequently, the way to build and operationalize AI is changing. Until a few years ago, data scientists would train their own models on very specific datasets and tasks. Now, we are shifting towards scenarios where huge organizations train models on large volumes of unlabeled data using a self-supervised objective, the so-called foundation models. These models can then be adapted by end users to perform many different specific tasks with small time-to-value. LLMs are a kind of foundation model trained on large volumes of text to predict the next word in a text. We also talk more and more about generative AI, which refers to the process of creating novel content by giving instructions (prompt) to foundation models trained on a huge amount of previously created content.
These techniques have enormous potentials: we can change the way we deal with customer support with the aid of AI-power chatbots, we can create a bunch of marketing and sales materials in few minutes, and we can have assistance while developing code. However, they are also affected by some limitations:
So, given the nature and limitations of these models, and the fact that we cannot directly train them on our specific domain, how can we use LLMs and adapt their responses to our needs? There are three possible techniques:
This consists by simply giving an instruction or task to the model and waiting for its response. There are a set of prompt engineering best practices that can be followed to achieve optimal results.
Moreover, there is the possibility of leveraging the so-called phenomenon of in-context learning: we can add a few examples (context) in our prompt, to help the model understand what kind of output we want to get.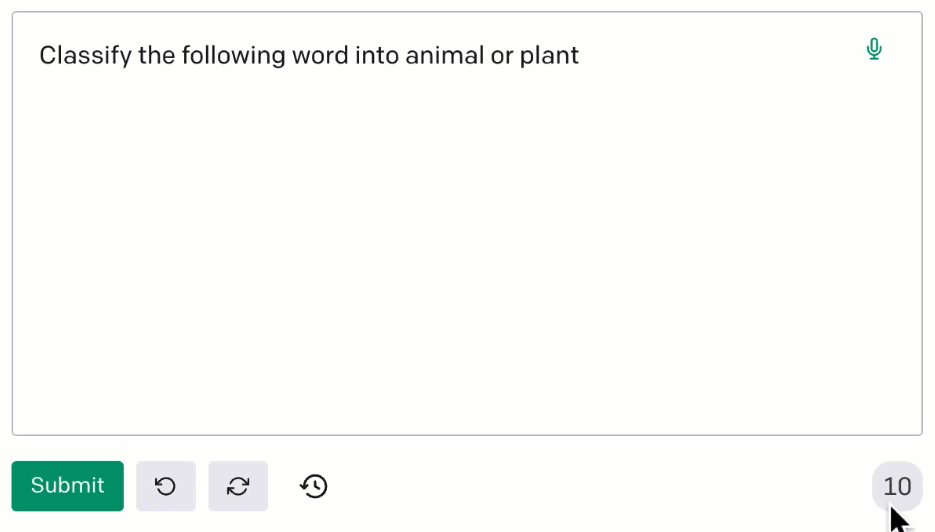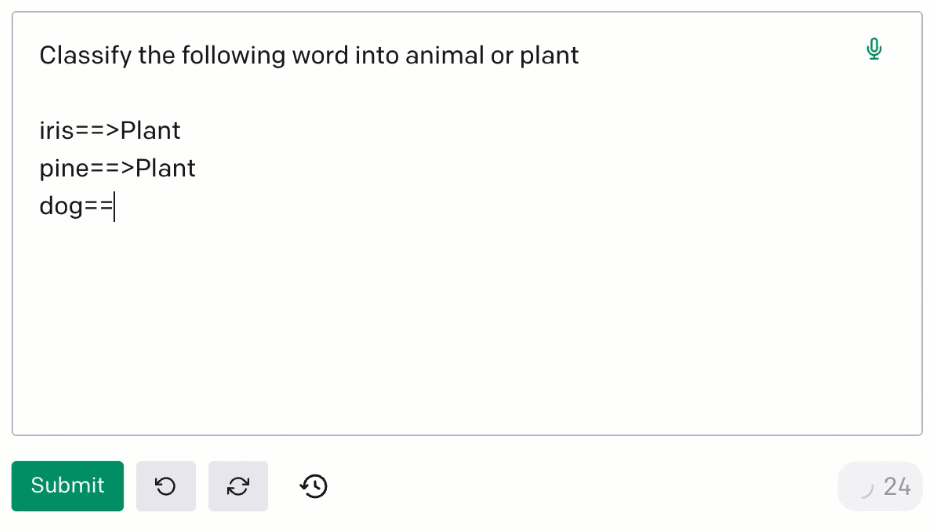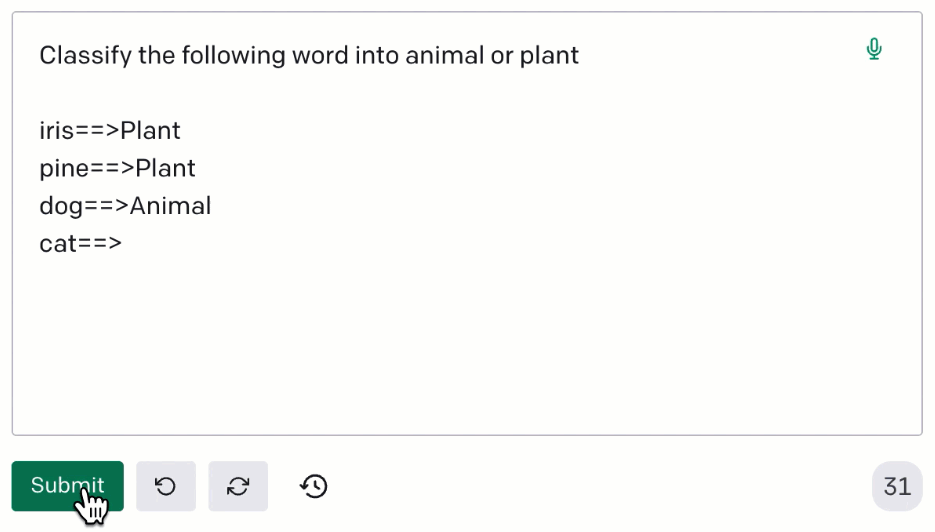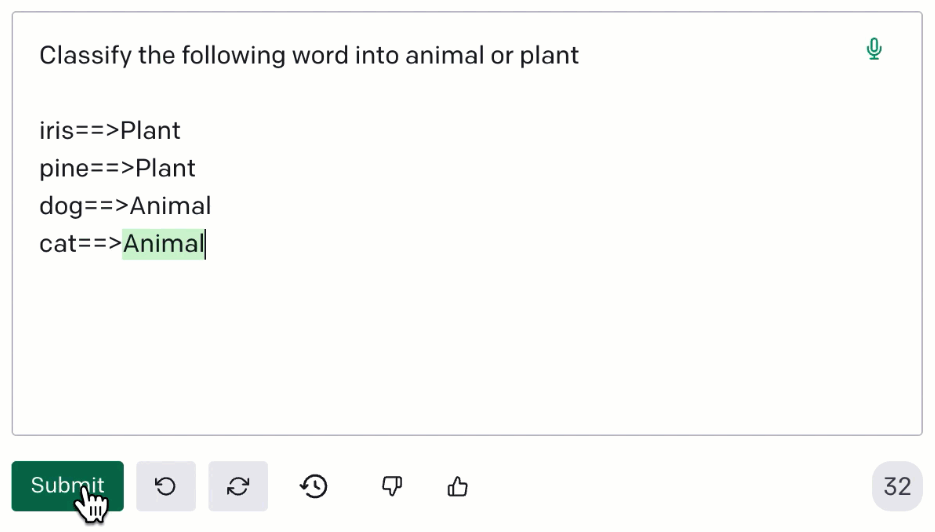
This is a quite impressive and mysterious capability of LLMs, that can adapt their behavior with no need of additional training epochs, just based on some examples, even in extreme cases when we ask them to go against the common sense learnt during training dataset:
This technique is based on the concept of text embeddings. Each model dealing with natural language processing has a fundamental step called text embedding, which transforms every piece of text, word, or sentence, into an array of numbers. Being an array, text can ultimately be represented as a point in a multidimensional space. In this space, two words or sentences with similar meaning will be close, while words with different meaning will be far apart.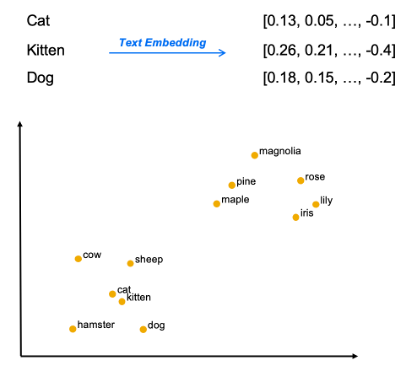
This concept of distance can be used for sophisticated tasks such as clustering, anomaly detection, knowledge base searches or classification of unlabeled data.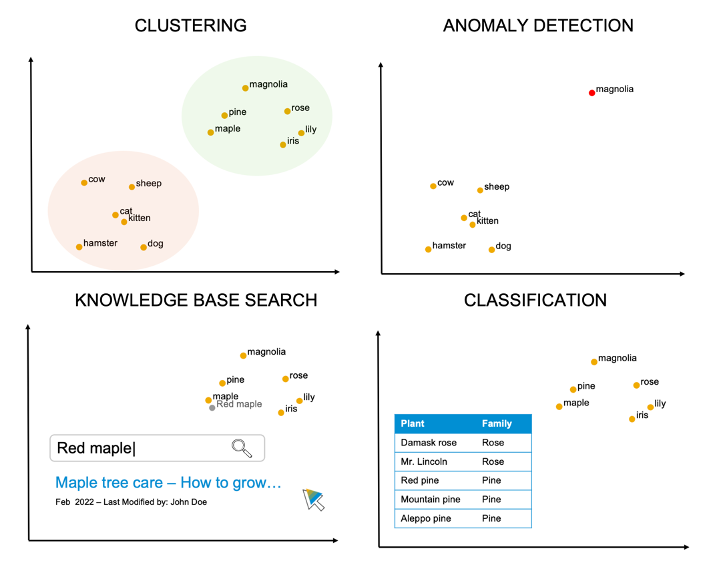
The third way of using LLMs is preparing a set of examples of prompts with a corresponding desired output, and submitting them to the LLM provider so that they can update the model using your own dataset. This is referred to as fine tuning, and it is a powerful way to adapt your model. Nevertheless, it requires the effort to put together a dataset of examples, which should not contain less than a few thousand instances, and which could be time consuming.
Later in this blog we will see how to deal with prompt engineering and embeddings.
When using LLMs and generative AI in general, it’s also important to be mindful about the risks of these techniques:
Our regulation framework is still not ready to govern these novel techniques. Legislators are now discussing on several questions posed by these models, for instance, which kind of data is legal to use for training these models, whether it is legal to store end-user prompts for retraining purposes, and how to deal with copyright on AI generated content. AI regulations are expected to come soon, and to impact our way of using the techniques. Hopefully, regulations will help us to get the most out of it while protecting our rights. A positive example is the ban of ChatGPT enforced in Italy in April 2023 due to privacy concerns. The ban was lifted only after OpenAI introduced a set of improvements to their service, including the possibility for end users to opt out from storage of their prompts for re-training purposes.
It's also important to keep in mind that, despite the popularity of OpenAI models, these are not the only ones available on the market. There is a variated landscape of models that comes under licensing or in some cases even opensource. The picture below can give you an idea. Before using these techniques, try to select models that offer the best cost-effectiveness balance in your specific use case.
For our prototype, we will be using GPT models. This are is accessible by either subscribing to OpenAI or to Azure OpenAI service. In the following, we will use the latter, but the services are equivalent. As for the GPT model version, we will be using GPT-3.5, but GPT-4 would do the job as well.
Let’s start to move into practice with an example. SA Lifestyle is a retailer selling small house appliances. They have a multichannel customer service, and they need a cloud solution to be able to automatically classify customer messages based on their content, so that generic compliments or complaints can be handled with an automatic reply, whereas technical issues, or product inquiries can be directed to the right services or personas. They would also like to extract insights from the incoming messages and have a dashboard where they can analyze recurrent trends and possible criticalities in the customer experience.

In the picture above you can get a sense of the functionalities required for the solution. Daniel, the SAP developer, and Christine, the SAP consultant, who are assisting SA Lifestyle in the project, agree that they will integrate GPT APIs to perform all the tasks related to text analysis and processing required to get insights from the customer messages. Moreover, they plan to use GPT as a code generator assistant to speed up the application development.
Below you can see the architecture of the solution they plan to build. The heart of the solution is the Intelligent Ticketing app built in using SAP Cloud Application Programming (CAP). It has three main services:
The following video gives you an end-to-end idea of the solution:
Large Language Models (LLMs) like GPT may have a significant impact on software development in SAP ecosystem, accelerating the development process by automating certain tasks, such as assist in generating code, writing documentation, and providing intelligent suggestions etc. In addition, these models could be integrated with your solutions on SAP BTP through APIs for tackling more intelligent use cases in various industries, such as answering questions about a knowledge base, analyzing texts, creating virtual conversational assistant etc.
These models have brought about a host of benefits, but they also come with limitations and potential risks that need to be considered. One challenge is the potential for generating incorrect output or even producing plausible hallucinations, which require human agent in loop for review and correction. One of the primary risks associated with LLMs is the ethical use of AI-generated content. LLMs have the potential to create fake news, generate inappropriate or harmful content, or facilitate malicious activities. AI ethical guidelines must be implemented to safeguards and to prevent misuse and ensure responsible use of these models. There are also concerns regarding data privacy and security, especially on sensitive or personal information, which you should carefully review the data privacy and security from these LLM vendors and implement your own data privacy and security guideline within your organisation on accessing these models.
Authors: yatsea.li, amagnani, edward.neveux, jacobtan
Disclaimer: SAP notes that posts about potential uses of generative AI and large language models are merely the individual poster's ideas and opinions, and do not represent SAP's official position or future development roadmap. SAP has no legal obligation or other commitment to pursue any course of business, or develop or release any functionality, mentioned in any post or related content on this website.
In addition, we are not in any position to give you any legal or commercial advice etc. about LLM providers, such as Azure OpenAI Service or OpenAI Service, which you should get in touch LLM providers directly. The source code of the sample solutions used in this blog post series are delivered as an SAP example under Apache 2.0 license with AS-IS manner. No SAP support available.
Introduction
Large Language Models (LLMs) like ChatGPT and GPT-4 have gained significant popularity with emergent capabilities. In this fourth session of the series, we’ll explore the potentials of GPT in SAP ecosystem, and discuss how SAP partners can leverage this powerful AI technology in combination with SAP technologies to accelerate their solution development processes, and create more intelligent solutions on SAP Business Technology Platform (SAP BTP).
Here list the full blog post series of Exploring the potential of GPT in SAP ecosystem.
In this blog post, we will start with an introduction to GPT and LLMs, discussing what they are, their potentials and limitations. Then, we will present the storyline of a retailer selling small house appliances, who wants to improve their multichannel customer service by building an intelligent ticketing service on SAP BTP. We will use this example to showcase two ways GPT can help in the implementation: first, we will see how to use GPT as a code assistant for an application in SAP CAP or RAP; secondly, we will see how to integrate GPT APIs in a CAP application.
We hope that by the end of this blog, you will have a better understanding of LLMs and how you can leverage their potential in your BTP solution.
Understanding ChatGPT and LLM
Given the huge attention ChatGPT raised, there are chances you have already at least heard something about it, or maybe even played with it. Let’s take however a few moments to understand what it is.
Quoting Wikipedia.org:
“ChatGPT is an AI chatbot developed by OpenAI. The "GPT" stands for generative pre-trained transformer—a type of large language model (LLM). It is based on OpenAI's GPT-3.5 and GPT-4 foundational GPT models, and has been fine-tuned [..] for conversational applications.”
So, at the heart of the technology are OpenAI foundational models, such as GPT-3.5 and GPT-4. ChatGPT is a chat bot built on top of these, that has been released and made available for anyone to use back in November 2022. This brought the latest trends and techniques in the AI research world to the attention of the public at large, so that now we are constantly hearing about all the technical words highlighted in the definition above. Let’s try to explain what they mean.
The key enabling technology is the transformer architecture. Transformers are a specific example of sequence-to-sequence models, that is to say, deep learning models that ingest a sequence of certain kinds of items (such as words if we are dealing with text, pixels if we are dealing with images, etc. ) and outputs a sequence as well, not necessarily of the same kind. For a simple example, think of a model that can translate a sentence from French to English.
Originally, these kinds of tasks were performed by architectures such as Recurrent Neural Network (RNNs) or Long Short-Term Memory (LSTM), that had some bottlenecks: first, they were not behaving well with large sequences, and second, they were not able to really understand and grab the context of sequences.
The scenario changed completely with the invention of transformers. Thanks to a technique called self-attention, these architectures were able to achieve better understanding of sequences and relationships between items of a sequence. Moreover, they could handle large sequences better, and they could be easily parallelizable for GPU computing. GPT models are not the only examples of transformers: for instance, if you type any question in the Google search bar, you will get an answer powered by BERT, the state-of-art technology back in 2018.
The various transformer architectures proposed over the years have been growing larger and larger in size, until with GPT-4 we reached about 1 trillions parameters, requiring various terabytes to be stored. With the growing size, the technology started to show unprecedented sequence understanding capabilities, and the opportunity of retaining an impressive amount of information learnt from training the large knowledge bases.
Consequently, the way to build and operationalize AI is changing. Until a few years ago, data scientists would train their own models on very specific datasets and tasks. Now, we are shifting towards scenarios where huge organizations train models on large volumes of unlabeled data using a self-supervised objective, the so-called foundation models. These models can then be adapted by end users to perform many different specific tasks with small time-to-value. LLMs are a kind of foundation model trained on large volumes of text to predict the next word in a text. We also talk more and more about generative AI, which refers to the process of creating novel content by giving instructions (prompt) to foundation models trained on a huge amount of previously created content.
These techniques have enormous potentials: we can change the way we deal with customer support with the aid of AI-power chatbots, we can create a bunch of marketing and sales materials in few minutes, and we can have assistance while developing code. However, they are also affected by some limitations:
- Efficiency – Being so large, foundation models require impressive resources and cost for training and operation.
- Updatability – Since their training is so expensive, it is hard to keep this model up-to-date.
- Reliability:
- Given the updatability constraints, information learnt by this model can be outdated and inaccurate. These models ignore anything that happened or was created after the latest training.
- They can ‘hallucinate’, producing false but plausible-sounding answers.
- They are stochastic in their behavior: minor variations in the prompts can lead to different responses. See for instance how in the example below GPT gave me 3 different answers to the same questions.

- There is no way to verify the correctness of the answers. In the example, we don’t know where exactly GPT took the information about SAP founding and we have no way to double check.
So, given the nature and limitations of these models, and the fact that we cannot directly train them on our specific domain, how can we use LLMs and adapt their responses to our needs? There are three possible techniques:
Prompt Engineering
This consists by simply giving an instruction or task to the model and waiting for its response. There are a set of prompt engineering best practices that can be followed to achieve optimal results.
Moreover, there is the possibility of leveraging the so-called phenomenon of in-context learning: we can add a few examples (context) in our prompt, to help the model understand what kind of output we want to get.
This is a quite impressive and mysterious capability of LLMs, that can adapt their behavior with no need of additional training epochs, just based on some examples, even in extreme cases when we ask them to go against the common sense learnt during training dataset:
Embeddings
This technique is based on the concept of text embeddings. Each model dealing with natural language processing has a fundamental step called text embedding, which transforms every piece of text, word, or sentence, into an array of numbers. Being an array, text can ultimately be represented as a point in a multidimensional space. In this space, two words or sentences with similar meaning will be close, while words with different meaning will be far apart.
This concept of distance can be used for sophisticated tasks such as clustering, anomaly detection, knowledge base searches or classification of unlabeled data.
Fine Tuning
The third way of using LLMs is preparing a set of examples of prompts with a corresponding desired output, and submitting them to the LLM provider so that they can update the model using your own dataset. This is referred to as fine tuning, and it is a powerful way to adapt your model. Nevertheless, it requires the effort to put together a dataset of examples, which should not contain less than a few thousand instances, and which could be time consuming.
Later in this blog we will see how to deal with prompt engineering and embeddings.
When using LLMs and generative AI in general, it’s also important to be mindful about the risks of these techniques:
- We should never take information provided in LLM responses for granted and to be true.
- We must be aware that biases do exist in the output out these models, as they were present in training data.
- Using LLMs can expose you to privacy concerns.
- It’s challenging to prevent these techniques from being used for unethical purposes.
Our regulation framework is still not ready to govern these novel techniques. Legislators are now discussing on several questions posed by these models, for instance, which kind of data is legal to use for training these models, whether it is legal to store end-user prompts for retraining purposes, and how to deal with copyright on AI generated content. AI regulations are expected to come soon, and to impact our way of using the techniques. Hopefully, regulations will help us to get the most out of it while protecting our rights. A positive example is the ban of ChatGPT enforced in Italy in April 2023 due to privacy concerns. The ban was lifted only after OpenAI introduced a set of improvements to their service, including the possibility for end users to opt out from storage of their prompts for re-training purposes.
It's also important to keep in mind that, despite the popularity of OpenAI models, these are not the only ones available on the market. There is a variated landscape of models that comes under licensing or in some cases even opensource. The picture below can give you an idea. Before using these techniques, try to select models that offer the best cost-effectiveness balance in your specific use case.
For our prototype, we will be using GPT models. This are is accessible by either subscribing to OpenAI or to Azure OpenAI service. In the following, we will use the latter, but the services are equivalent. As for the GPT model version, we will be using GPT-3.5, but GPT-4 would do the job as well.
Exploring GPT in the SAP ecosystem with a sample

Let’s start to move into practice with an example. SA Lifestyle is a retailer selling small house appliances. They have a multichannel customer service, and they need a cloud solution to be able to automatically classify customer messages based on their content, so that generic compliments or complaints can be handled with an automatic reply, whereas technical issues, or product inquiries can be directed to the right services or personas. They would also like to extract insights from the incoming messages and have a dashboard where they can analyze recurrent trends and possible criticalities in the customer experience.

In the picture above you can get a sense of the functionalities required for the solution. Daniel, the SAP developer, and Christine, the SAP consultant, who are assisting SA Lifestyle in the project, agree that they will integrate GPT APIs to perform all the tasks related to text analysis and processing required to get insights from the customer messages. Moreover, they plan to use GPT as a code generator assistant to speed up the application development.
Below you can see the architecture of the solution they plan to build. The heart of the solution is the Intelligent Ticketing app built in using SAP Cloud Application Programming (CAP). It has three main services:
- Ticketing service, that keeps a record of the customer communication history
- LLM Proxy service, which integrates GPT APIs to analyze the content of customer messages and classify them accordingly.
- Orchestrator service, which based on the classification of the incoming customer messages performed by the LLM Proxy services, routes the messages to the appropriate processing options. It integrates with the Business Rules service in SAP Build Process Automation, and with SAP Field Service Management for customer issues requiring a service call.

The following video gives you an end-to-end idea of the solution:
Further resources
- The source code of the sample Intelligent Ticketing Solution
- SAP and generative AI
- Introduction to GPT by OpenAI
- Open LLM Leaderboard on Hugging Face
Wrap up:
Large Language Models (LLMs) like GPT may have a significant impact on software development in SAP ecosystem, accelerating the development process by automating certain tasks, such as assist in generating code, writing documentation, and providing intelligent suggestions etc. In addition, these models could be integrated with your solutions on SAP BTP through APIs for tackling more intelligent use cases in various industries, such as answering questions about a knowledge base, analyzing texts, creating virtual conversational assistant etc.
These models have brought about a host of benefits, but they also come with limitations and potential risks that need to be considered. One challenge is the potential for generating incorrect output or even producing plausible hallucinations, which require human agent in loop for review and correction. One of the primary risks associated with LLMs is the ethical use of AI-generated content. LLMs have the potential to create fake news, generate inappropriate or harmful content, or facilitate malicious activities. AI ethical guidelines must be implemented to safeguards and to prevent misuse and ensure responsible use of these models. There are also concerns regarding data privacy and security, especially on sensitive or personal information, which you should carefully review the data privacy and security from these LLM vendors and implement your own data privacy and security guideline within your organisation on accessing these models.
Labels:
3 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
95 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
67 -
Expert
1 -
Expert Insights
177 -
Expert Insights
311 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
GraphQL
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,576 -
Product Updates
354 -
Replication Flow
1 -
REST API
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
443 -
Workload Fluctuations
1
Related Content
- Elevate Your Business with AI at SAP Sapphire 2024 Orlando! in Technology Blogs by SAP
- The 2024 Developer Insights Survey: The Report in Technology Blogs by SAP
- SAP Datasphere + SAP S/4HANA: Your Guide to Seamless Data Integration in Technology Blogs by SAP
- IoT - Ultimate Data Cyber Security - with Enterprise Blockchain and SAP BTP 🚀 in Technology Blogs by Members
- Hack2Build on Business AI – Highlighted Use Cases in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 18 | |
| 16 | |
| 12 | |
| 11 | |
| 9 | |
| 8 | |
| 8 | |
| 8 | |
| 7 | |
| 6 |