
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Data Analytics Solution using SAP Business Technol...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Employee
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
11-07-2023
6:37 PM
An approach to address data security in case of regulated industry
Introduction
SAP Business Technology Platform (BTP) is SAP public cloud offering and a collection of 90+ SaaS and PaaS fully managed services. Various customers are onboarding BTP and deploying solutions across application development & automation, extended planning & analytics, data & analytics, integration, and AI, to achieve business outcomes. Refer to SAP Discovery Center for details.
One of the important pillars of BTP is data & analytics which has various services including those for data governance, data lake and datawarehouse. As part of the SAP strategic customer program, I got an opportunity to engage, architect and propose an end-to-end data analytics transformation roadmap for an FSI/banking customer with global operations and headquartered in SEA.
The roadmap comprises of more than 25 BTP services, significant of which are mentioned below, covering data persistency and business data fabric requirements.
- HANA Cloud (for data persistency, big data, data lake)
- Datasphere (for datawarehouse, business data fabric, data democratization)
- Data Intelligence (for data integration, metadata management)
- Build Services (for application development, automation, content management)
Various business use cases and personas were identified, to be implemented and onboarded over subsequent 3+ years, as part of finance data & analytics transformation initiative, from the areas including capital, liquidity, client MI, finance back office and strategic planning & reporting.
Since the customer is from highly regulated industry, they had to undergo strict and lengthy compliance and regulatory approval procedures from internal and external bodies before they could onboard the public cloud SAP BTP services. Majority of the of the requirements were related to data security, cloud operations and resilience of various data assets which forms the foundation of above-mentioned business use cases.
To address the same, in collaboration with SAP cybersecurity team, I had put across a “secure data vault” framework, which is multi layered in structure and takes care of the requirements and objections raised by various stakeholders from data security perspective. The approach has been discussed below, and can be replicate, fine-tuned further and reused for other similar customer situations.
The “Secure Data Vault” Framework
Diagrammatically the framework can be represented as shown below. I will subsequently provide further detail, about each layer, bottom up. Each subsequent subsection/layer discusses the technical considerations emanating from general to more specific cloud resiliency and data security requirements in regulated industry context. Proposed solution and architecture approach has been provided thereafter.

Multilayered “Secure Data Vault” Framework
Please note that the features, functionalities discussed in subsequent sections are continuously evolving for good and subject to change in future, based on decision made entirely by SAP, at various times. Customer and partners can track the evolving product roadmaps in SAP product roadmap explorer page, which is available publicly.
Cloud Operations, Resiliency, and High Availability
This layer addresses general SLA, DR, and HA requirements, for any onboarded cloud service. SAP provides SLA guarantees (please visit SAP Trust Center for agreements) and details as to how it manages HA, DR, and backup recovery for all BTP services. It is a good practice to compile, review and submit, all of the below considerations for entire solution, across various SaaS and PaaS component services:
- Single Zone HA/ Multi Zone HA.
- How the service ensures HA.
- Guaranteed SLA by SAP.
- If customer data will be persisted or not.
- Disaster recovery, what happens if primary AZ goes down.
- Backup & recovery – frequency, retention period, procedure, and type of storage used.
Above is expected to provide confidence and clarity to customer about SAP BTP platform, operations, and resiliency procedures, and help to reduce the time, generally lost in repeated questions - back & forth, communications gaps and complicated discussion threads.
An example outcome of the above, shown as below.

General SLA, HA, and Resiliency Procedures
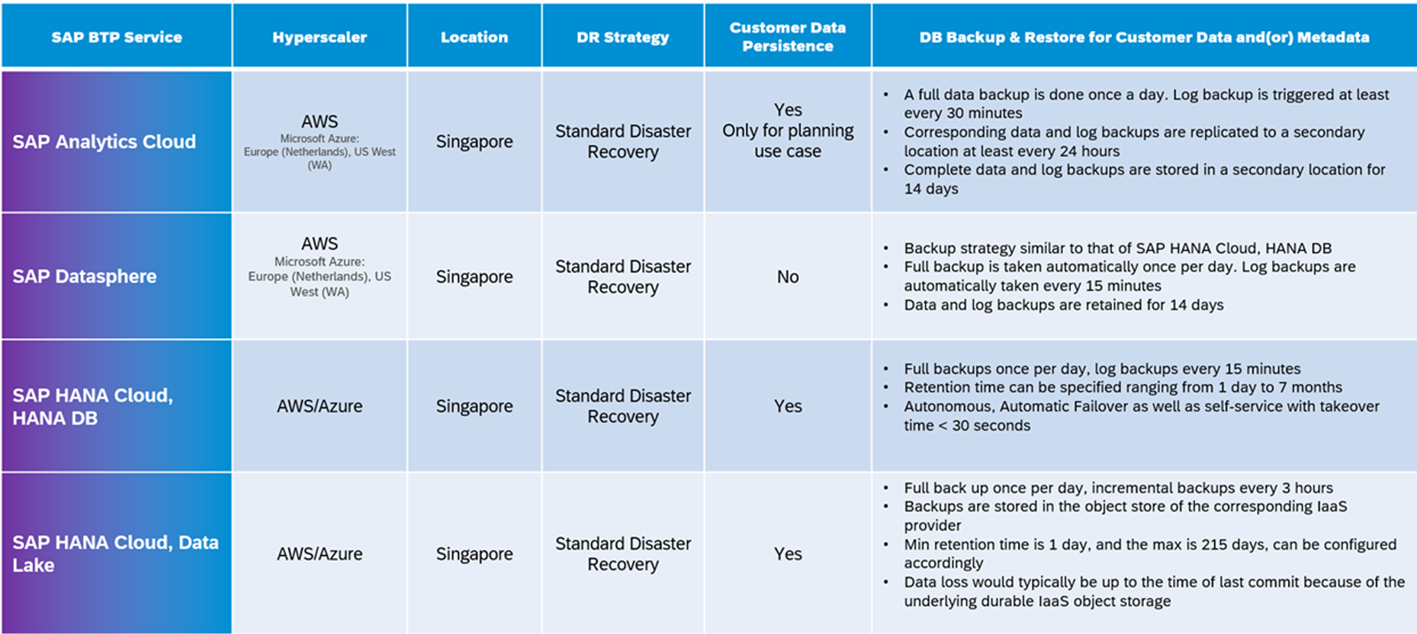
Hosting Details DR Back Recovery Strategy
Above documentation for all BTP services is available as part of product documentation at SAP Help Portal.
Generally, more details are available in standard formats with various SAP internal teams and can also be shared with partner and customers on demand. The sample information published above is as of Q3’ 2023 and continuously evolving. Hence it is subject to change in future, by SAP, at various times. Customer and partners can track the evolving product roadmaps in SAP product roadmap explorer page, which is available publicly.
Segregated and Isolated Semantics and Storage Layer
Since data security and resiliency requirements, for data persistency are stricter, hence it is generally a good practice to limit data persistency in cloud and isolate persistency and semantics layer. The impact of the same on overall solution architecture should be clearly stated in solution design document along with technical design considerations & principles. A sample is provided below in context to mixed SAP and non-SAP landscape, hybrid architecture, ERP, applications, and databases:
- Specific scenarios called out which need data to be stored in cloud vs federation, for example the query requires in memory acceleration and the data need to be close to consumption layer.
- SAP ERP and application’s data best persist and analysed using BTP, so that the SAP provided semantics layer and out of the box business content can be preserved and leveraged.
- Persistence of aggregated vs transactional data, as much as possible data should be first aggregated and then moved to cloud. Transactional/detailed data persistence should be called out.
- Data which does not need to be persisted in cloud should be just federated from on premise/private/public cloud to the semantics layer/Datasphere using cloud connector (CC) for SAP and DP Agent for non-SAP sources.
- Data which will be persisted in cloud, will be stored in data lake/HANA Cloud only, because of the following reasons, from data security and resiliency perspective:
- HANA Cloud provides better and flexible SLA options for data storage, by default, as opposed to other BTP services. Comparison of SLAs and options to enhance the same should be highlighted.
- HANA Cloud provide options to enhance SLA using sync and async replicas, if needed. There are roadmap items for cross region async replica and multiple replicas in same AZ. Read replicas are also planned for read intensive queries.
- In addition to SAP managed encryption, provided by default in HANA Cloud, customer managed encryption (BYOK, HYOK) and tokenization scenarios can be implemented. Such architecture patterns and flow of data, keys & tokens should be documented.
Below is the simplified diagrammatic representation of the above strategy and a sample of isolated persistency, semantics, and consumption layer articulated. Note that if there are non-SAP targets which need to connect, for analysis or ML/AI then the same should also be shown for e.g., using SAP FedML libraries with Databricks so that data does not have to be transferred physically for ML/AI model training but instead just federated connection between Datasphere and Databricks is used. Less data movement means less surface area & risk of data breach.

Simplified Solution Architecture Representation
Reiterating the strategy, in the ongoing example, it was decided to not persist any data in Datasphere and use it to build unified modelling layer instead, exposing semantics to various personas for consumption. This design decision made architecture clean, modular, and robust from security and resiliency perspective.
However, the above design decision also opened certain issues for consideration, as mentioned below, which are not subject to the current blog, but I am expecting to cover the same later in another blog:
- Concurrency impact on query performance in case of federation and multi cloud scenarios.
- How to evaluate pushdown effectiveness in case of single vs multiple SAP and non-SAP sources.
- How to size Datasphere tenants, which can cater to all identified use cases for business data fabric & data democratization, at the same time honouring performance & availability KPIs in case of expected load.
Secondary networking and infrastructure components should also be laid out, if necessary for example in above case that of SAP DP Agent and CC. Here it is important to document these because of the role they play for data integration from non-SAP sources and as a reverse proxy respectively. In case of SAP solutions please note that DP Agent is a collection of HANA Smart Data Integration (SDI) drivers which are used to connect non-SAP data sources using JDBC. SAP Cloud Connector (CC) is used as a reverse proxy to ensure that in due course of operations, only outbound connection is exposed to public cloud and rest of on premise/private cloud databases and applications remain abstracted beyond firewall.
Inbuilt/ by default Data Security for Data in Motion and Data at Rest
Data persistence layer is subjected to more stringent data security requirements. Moreover, concerns are generally raised when data need to transit through public internet. Specifically in the ongoing example, since HANA Cloud private link is not available as of Q3’2023, but planned for 2025 (subject to HANA Cloud roadmap at the link) hence detailed networking architecture was provided. Anyhow it should at least be highlighted as to how data transits across HTTPS i.e., encrypted using TLS and remains on the hyperscaler backbone in case of single hyperscaler vendor’s public/private cloud to SAP cloud scenarios. However, in case of multi cloud vendors and/or hybrid scenarios involving on premise, data inevitably transit through public internet, unless private link or VPN is used. However, in SAP case, in ongoing example it was clearly articulated how data, while it will go through public internet, still because of network encryption using TLS, it is secured.
Moreover, since HANA Cloud was positioned as unified data storage for entire solution hence its native data security capabilities were highlighted and documented to make the data security POV stronger. There already is ample documentation on HANA Cloud security which can be found at the link.
As a best practice, within the data which can be persisted in cloud, it is best practice to have separate data security strategy for non PII vs PII data. There might be security vs performance vs cost trade-off hence in the ongoing example also, for non PII data, the following native security capabilities in HANA Cloud, were articulated, documented, and planned to be implemented:
- SAP managed data encryption using AES 256. Specific details about the master keys, where the same are stored and how these are protected was shared.
- Data masking and anonymization capabilities of HANA Cloud. Note that Data Intelligence (DI) also has native operators for data masking and anonymization but the difference between the two approaches is – data masked and anonymized by DI is transferred into HANA Cloud in transformed format which cannot be restored in original form, but this is not the case with HANA Cloud native masking and anonymization. Hence it was decided to use HANA Cloud as masking and anonymization engine instead of DI.
- Additional level of security in Datasphere, data access controls which is applicable at row level while the data is consumed through semantics layer.
HANA Cloud by default, provides SAP managed encryption, but customer wanted to have more control on encryption and integrate with their existing secrets management solution e.g., Fortanix. Such BYOK and HYOK scenarios, in SAP case, need additional SaaS solution known as SAP Data Custodian Key Management Solution (DC KMS). Such additional possible security controls, which need additional investment but offer tighter customer controls should be documented and articulated with cost benefit analysis. In the ongoing example BYOK and HYOK scenarios were discussed and evaluated with customer in detail and helped to secure necessary approvals from security perspective.
Encryption using Customer Managed Keys (BYOK)
As discussed at the end of last section, it was given as a requirement to be able to use own randomly generated keys for data encryption. Currently encryption supported in HANA Cloud is based on AES 256 algorithm and entirely managed by SAP. It was thought to have customer manage their own keys for data encryption in HANA Cloud, so that in long term more business use cases can be onboarded on BTP quickly and having to face lesser approvals & regulatory requirements. So BYOK and HYOK scenarios goes a long way to prove & establish data security capabilities of a given solution, and hence should at least be tabled for a POC, even though it might not be needed in the short term.
Following is an example as to how DC KMS is expected to work with HANA Cloud and help to achieve BYOK. BYOK scenario using DC KMS has been documented here. Note that the functionality of DC KMS itself is still evolving, hence the below architecture and steps might look different in future. However, it’s use case for HANA Cloud is well documented here at the link.

DC KMS architecture with HANA Cloud for BYOK
DC KMS BYOK uses CKM_RSA_AES_KEY_WRAP defined as part of standard PKCS#11, and works as follows:
- A sender generates a random AES encryption key (the "wrapping key"), which they want to send to a receiver.
- The sender encrypts the wrapping key with the receiver's RSA public key, creating a "wrapped" key. This wrapped key is then sent to the receiver.
- The receiver uses their RSA private key to decrypt the wrapped key, revealing the original AES wrapping key.
- The receiver can then use the AES wrapping key to encrypt and decrypt data.
Note that the functionality of DC KMS itself is still evolving, hence the above architecture and steps might look different in future. However, it’s use case for HANA Cloud is well documented here at the link. The same is also applicable for rest of the BTP services, which offer data storage (depending on DC KMS current and future roadmap, which may change time to time), but having an isolated data persistence layer, again proves to reduces the complexity of implementation, hence more reasons to plan a modular architecture.
Tokenization and Detokenization of PII Data
As discussed in previous sections it makes lot of sense to propose an additional layer of security for PII data. It opens greater possibilities for the customer to leverage solution for more unforeseen use cases in future, because in a regulated industry new solution is not easy to onboard hence existing proven ones have more chances to get utilized. This leads to cross sell and up sell opportunities and inline with SAP LACE methodology as well which focuses on “Land”, “Adopt”, “Consume” and “Expend”.
The customer in the ongoing example, is using protegrity tokenization solution, they wanted SAP BTP solution to integrate with, only for PII data, which they plan to bring into HANA Cloud. The process flow is going to be as follows:
- Tokenize columns having PII information before moving the data to HANA Cloud. Tokenization to happen via existing protegrity server before moving data into HANA Cloud.
- When reading the data out from HANA Cloud through various channels, for example through SAC and Datasphere, PII columns to be detokenized using an API call to protegrity server and rendered in readable format.
Below solution, which is represented diagrammatically as well, was proposed, which is being evaluated by customer using proof of concept. If successful, it will open new possibilities to bring PII data into HANA Cloud, hence increasing the data footprint in BTP.

Tokenization and Detokenization Process with SAP BTP
Please note that the above is for illustration purpose only and should be tested and tried in specific cases. In SAP cases, this is based on ability to create HANA calc views and call an external API to detokenize the data. This also uses federated live link between data persistency/HANA Cloud and Semantics/Datasphere, Consumption/SAC BI & Planning layer. For non-SAP solutions above concept is still desirable but as a general practice trade-off between cost to implement, performance while consuming the data/detokenization and security benefits should be evaluated especially in case of multi-cloud and/or hybrid scenarios. Hence, I said previously that data to be persisted in cloud, needs to be categorised and security strategy should be proposed, evaluated, and documented thoroughly. This call for additional tools including those for cataloguing, but data management subject is out of the scope of current blog, and I would want to discuss later as part of DAMA compliant data management practices/blogs (note that DAMA compliant means those listed in Data Management Body of Knowledge, but entirely based on my personal interpretation of the same and not officially or unofficially endorsed by DAMA).
Conclusion and Key Takeaways
In the blog we saw how I managed data security and resiliency discussions with a fictitious customer from highly regulated industry by providing multi layered security framework. There are detailed golden and knowledge assets which are available and can be leveraged in similar situations, by SAP internal teams, partners, and customers, especially when SAP BTP is to be proposed and implemented in regulated industries like FSI/banking, for data & analytics use cases. Having said that the concepts can be applied to non-SAP solution stack as well, in which case there might be certain specifics, designed and implemented differently.
Key takeaway is to understand how we can drive standalone SAP BTP or in general Data & Analytics led enterprise-wide transformation initiatives, by focusing on outcome, building the business case across functional areas, step by step and alleviate customer’s concerns on surrounding aspects like security, cloud operations and resiliency.
Please feel free to reach out for more details on the above or on other topics like those on “Master Data Management for Analytics using SAP BTP”, “ML Ops framework using SAP BTP” and “Leveraging SAP BTP for Customer 360 and Campaign Automation”.
- SAP Managed Tags:
- Data and Analytics,
- Banking,
- Security,
- SAP Business Technology Platform
Labels:
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
93 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
67 -
Expert
1 -
Expert Insights
177 -
Expert Insights
301 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
GraphQL
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
346 -
Replication Flow
1 -
REST API
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
430 -
Workload Fluctuations
1
Related Content
- Sapphire 2024 user experience and application development sessions in Technology Blogs by SAP
- Expanding Our Horizons: SAP's Build-Out and Datacenter Strategy for SAP Business Technology Platform in Technology Blogs by SAP
- Supporting Multiple API Gateways with SAP API Management – using Azure API Management as example in Technology Blogs by SAP
- Consuming SAP with SAP Build Apps - Mobile Apps for iOS and Android in Technology Blogs by SAP
- Improving Time Management in SAP S/4HANA Cloud: A GenAI Solution in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 29 | |
| 17 | |
| 15 | |
| 13 | |
| 11 | |
| 9 | |
| 8 | |
| 8 | |
| 8 | |
| 7 |