
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- A Journey into Retrieval-Augmented Generation (RAG...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Product and Topic Expert
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
09-19-2023
6:54 PM
Introduction
Artificial Intelligence (AI) has woven itself into the fabric of numerous industries, and SAP stands at the forefront of integrating AI into its cloud solutions. In this blog post, we embark on a small experiment around Generative AI on BTP using Python and Hana Cloud. Our focus? An engaging experiment featuring a chatbot powered by the Retrieval-Augmented Generation (RAG) technique. We'll delve into the chatbot's architecture, present some interesting results, and discuss key findings along the way.
SAP's Generative AI Initiatives
SAP is committed to harnessing the power of AI to enhance its applications and provide more value to its users. Our Executive Board Members, Juergen Mueller and Thomas Saueressig, highlighted Generative AI as a disruptive technology with significant potential to enhance customer value.
Generative AI, a form of AI that can produce text, images, and diverse content, plays a pivotal role in SAP's innovation strategy. SAP integrates Generative AI with industry-specific data and deep process knowledge to create AI capabilities that are both built-in and relevant to businesses. SAP offers several AI technologies and many business processes infused with AI: On BTP, SAP offers AI Core with AI Launchpad and a number of AI Business Services ready to integrate by our customers.
One of SAP's key principles in AI development is responsibility and trustworthiness. SAP aims to provide unbiased and sustainable AI support while ensuring transparency, data protection, and privacy. Thomas Saueressig, emphasizes the importance of ethical standards in AI development, especially with the rapid rise of Generative AI1.
Collaboration Fuels AI Innovation: SAP has strategically partnered with tech giants such as Microsoft, Google, and IBM to bolster its Generative AI capabilities. Additionally, SAP has made substantial investments in leading language model (LLM) providers like Aleph Alpha, Cohere, and Anthropic, signifying its commitment to expanding the horizons of Generative AI.
The Experiment: Chatbot Using Retrieval-Augmented Generation
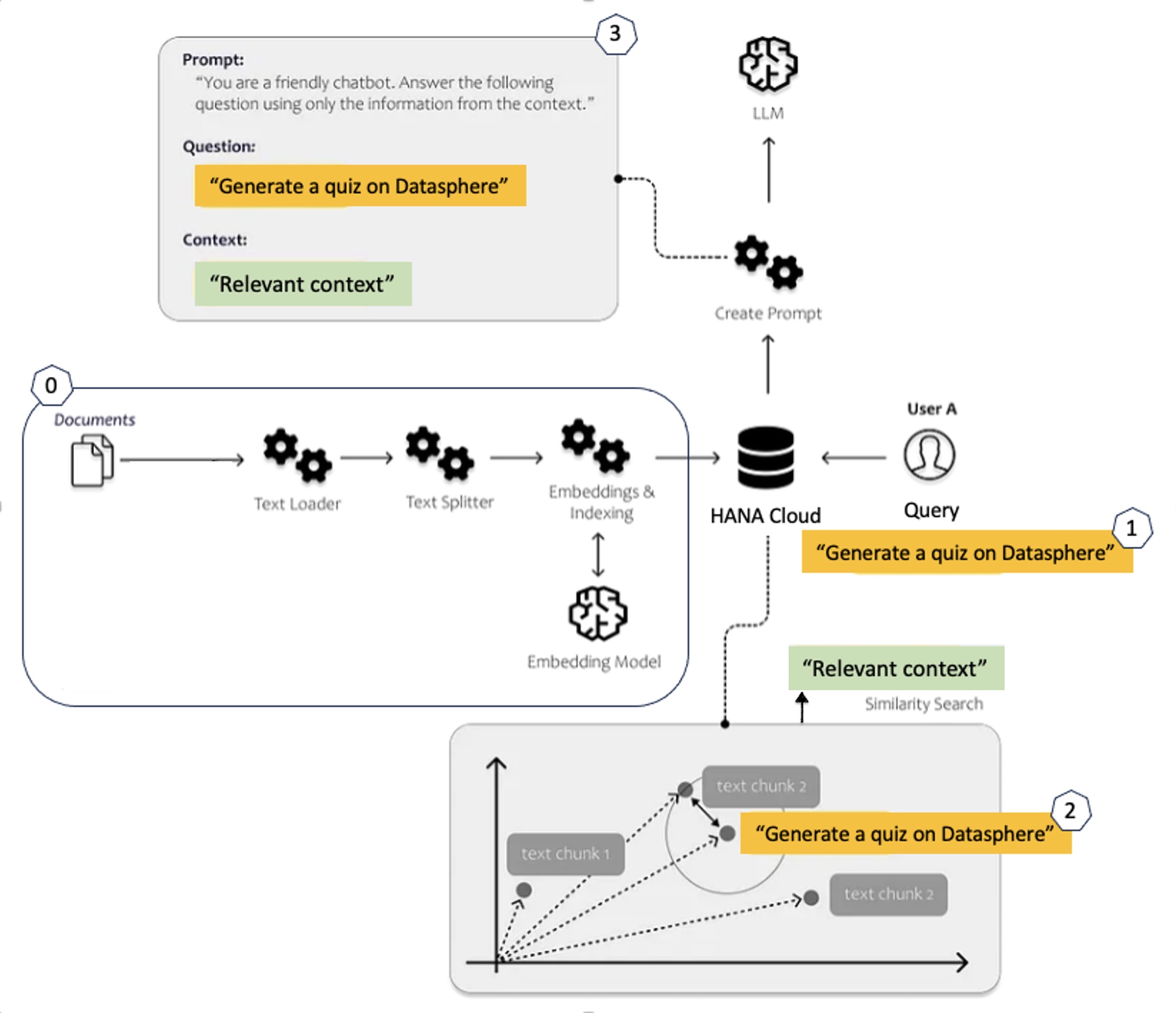
To explore the potential of Generative AI, I embarked on an experiment using the Retrieval-Augmented Generation technique. The implementation of this experiment is based on this tutorial6 and further enriched with OpenAI Python libraries and Hana Cloud. The primary objective was to create a chatbot tailored to assist with S/4HANA Cloud and BTP advisory tasks.
Why Retrieval-Augmented Generation (RAG)? because RAG makes it possible to answer queries beyond the realm of LLM training data. For example, it will be capable of answering questions related to SAP DataSphere as this is a new product not known by the OpenAI models as of September 2021. In addition, RAG helps in mitigating the risk of generating fabricated answers. In essence, Retrieval-Augmented Generation represents a sophisticated form of programmatic prompt engineering.
Usually, RAG relies on embeddings to build the most relevant context. An embedding is a mathematical representation of a chain of tokens in a multidimensional space. On such multidimensional space, related tokens or set of tokens can be close to each other on a certain number of axis and distant on some other axis. So, calculating distances between embeddings vectors allows us to achieve context-based search and text extraction.
The following diagram shows a hypothetical (made for an educational purpose) 3-dimensional space laying out some BTP related technologies.

According to such a system, the word “Datasphere” will be represented with following coordinates or features.
| text | embeddings |
| Datasphere | "[0.20 , 0.80 , -0.20]" |
From this diagram, we can say that Analytics cloud is close to Datasphere within the context of Data platforms axis and distant on the Development tools axis.
In the example above, the embedding vector has only 3 dimensions; OpenAI’s generated Embedding vectors have 1536 dimensions capturing the position of keywords in a rich system of dozens of contexts.
RAG process can be summarized as follows:
0- Data preparation
a- Gather the initial data (PDF, HTML, MD, etc. files) constituting our corpus of knowledge
b- Split the data into small chunks not exceeding a certain number of tokens
c- Generate embedding vector for each chunk
For this step of data preparation, I used the following:
Tokenizer: cl100k_base
Embedding engine: text-embedding-ada-002
max_tokens = 256
The python statements are:
df['embeddings'] = df.text.apply(lambda x: openai.Embedding.create(input=x, engine='text-embedding-ada-002')['data'][0]['embedding'])d- Store the embeddings in HANA Cloud
Using the OpenAI’s Python library, the generated embeddings vector array size is 1536 elements of float values with 18 decimals (Note for such use case, the number of decimals could be reduced to a much smaller number e.g., 3 without losing precision). This would reduce dramatically the embeddings file size and reduce a bit the response time of the Pandas-based semantic search. The following is a truncated example of an embedding vector and table schema on Hana Cloud:
| id | text | n_tokens | embeddings |
| 0 | "text chunk.... " | 200 | "[0.021088857203722, -0.0266727302223444, 0.012524755671620369, ...]" |

e- Load the embeddings to the Python app
result = cursor.execute("SELECT * FROM EMBEDDINGS").fetchall()
serving_df = pd.DataFrame(result, columns=["id","text","n_tokens","embeddings"])
serving_df['embeddings'] = serving_df['embeddings'].apply(lambda x: np.array(eval(x)))1- Get the user query and calculate its embeddings
q_embeddings = openai.Embedding.create(input=question,
engine='text-embedding-ada-002')['data'][0]['embedding']2- Build the prompt context
a- Calculate distances between user’s query embeddings and the embeddings of the whole corpus
serving_df['distances'] = distances_from_embeddings(q_embeddings, self.serving_df['embeddings'].values, distance_metric='cosine')b- Retrieve text chunks associated to the closest embeddings (context)
for i, row in self.serving_df.sort_values('distances', ascending=True).iterrows():
context.append(row["text"])3- Build the prompt (system message, user question, question) and call OpenAI’s completion API
For this step, the following is used:
Completion model: gpt-3.5-turbo-16k
max_len = 8192 (max number of tokens question + answer)
Results and key findings
0- Data preparation
As indicated earlier, I used the Tokenizer cl100k_base and the Embedding engine text-embedding-ada-002 and max_tokens = 256 for the generation of the embeddings.
Expect the embeddings file to be about 10 time bigger than the original content size for the chosen max_tokens size of 256. As the max_tokens go up the embeddings size goes up but the quality of the similarity search may become worse.
According to my experiment, 125M text content gave 24M real content (stripped of metadata, markup) which gave about 700M embeddings file.
It takes 5 minutes to generate the embeddings for a file of 3M using no multithreading nor multiprocessing. Using multiple threads or multiple processes should speed up this task; however, you need to handle rate limit conditions when reached, for example, by adding a timeout of one minute max.
It takes 1.5 minutes to load 700M of embeddings from Hana Cloud to the Python App (this is not a problem as it’s done once at the start of the App and can be sped up easily)
1- Get the user query and calculate its embeddings
Creating the embedding of the question takes 0.2s to 0.6s
2- Build the prompt context
Search and Retrieve text chunks takes 1.5s
3- Build the prompt (system message, user question, question) and call OpenAI completion API
Calling and getting a response from the OpenAI completion AP takes 3s a 5.5s
Conclusion
Total response time: 4.7s to 7.7s
From the above results, it’s safe to say that using a file system or Hana Cloud to store the embeddings and using Pandas DataFrame to process the similarity search based on cosine shortest distances is a reasonable choice for many of your use cases. The above results can be enhanced by 1) reducing the number of decimals of the embeddings vector values to three decimals 2) by using indexing using a library like ScanN or by adding parallel processing of the similarity search task on Pandas DataFrame, 3) optimizing the context sent to OpenAI as bigger context tend to increase the response-time.
As everyone would assume, SAP HANA Cloud will most likely add a vector database in the near future but in the meantime, the technic provided in this article can be used in some of your implementations. In case a Vector database is really required, the PostgreSQL service can be used on BTP.
I hope this blog will help some of you clarify some of the questions you might have and now feel ready to jump in to the world of GenAI. As a partner, if you need advisory, we offer free service for S/4HANA Cloud extensibility and BTP technical advisory
If you were curious about the final result, here you can see the Chatbot UI showing a question and answer about Datasphere.

In terms of architecture, I following the tutorial architecture and just added to it SAP Build Apps for the frontend and the OpenAI integration from the Python backend.

Other work from SAP colleagues
Here list the full blog post series of Exploring the potential of GPT in SAP ecosystem:
References:
- SAP AI Ethics
- SAP AI roadmap2023 and 2024
- SAP AI Core
- SAP AI Launchpad
- SAP AI Business Services
- Create an Application with Cloud Foundry Python Buildpack
- How to Process Large Pandas DataFrame in Parallel
- OpenAI’s Tokenizer
- Azure OpenAI Service Documentation
- OpenAI QuickStart documentation
Labels:
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
93 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
67 -
Expert
1 -
Expert Insights
177 -
Expert Insights
301 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
GraphQL
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
346 -
Replication Flow
1 -
REST API
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
430 -
Workload Fluctuations
1
Related Content
- CSGOEmpire Referral Code 'BONUSGO': Get 3 Free Cases in Technology Q&A
- Get More Gems and Blast Gold with DistrictOne Invite Code '8OXCBF' in Technology Q&A
- Claim Your Welcome Bonus with CSGOEmpire Promo Code 'BONUSGO' in Technology Q&A
- Get Your Welcome Bonus with Rollbit Referral Code 'GAMBLEGUYS' in Technology Q&A
- Aries Markets Invite Code 'kl3sfi': Boost Your XP Points in Technology Q&A
Top kudoed authors
| User | Count |
|---|---|
| 30 | |
| 17 | |
| 15 | |
| 13 | |
| 11 | |
| 9 | |
| 8 | |
| 8 | |
| 8 | |
| 7 |