
- SAP Community
- Products and Technology
- Financial Management
- Financial Management Blogs by SAP
- How does SAP HANA Search work in SAP Global Trade ...
Financial Management Blogs by SAP
Get financial management insights from blog posts by SAP experts. Find and share tips on how to increase efficiency, reduce risk, and optimize working capital.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Product and Topic Expert
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
03-07-2023
5:07 AM
Companies running SAP GTS 11 on an SAP HANA database can utilize SAP HANA Search in Sanctioned Party List Screening (SPL) in addition to classic GTS Search and TREX. However, with the introduction of SAP GTS, edition for SAP HANA, TREX is no longer an option.
As GTS users are moving from TREX to SAP HANA Search, it is crucial to understand how the SAP HANA Search differs. If you apply the same parameter settings as with TREX, GTS will produce a different outcome, and you may therefore raise questions about its reliability. So, for starters, you should definitively not copy the parameter settings directly from TREX.
SAP HANA Search in GTS relies heavily on the search capabilities in the HANA database and not GTS-specific logic run on the application server. Consequently, SAP HANA Search does not utilize some of the parameters you traditionally define in SAP GTS, such as, for instance, the delimiters. Delimiters separate a search string into separate words or “tokens”. Delimiters ensure that a Business Partner entry like “Erika Mustermann” is handled as two different search terms (“Erika” and “Mustermann”) and not as one search term (“Erika Mustermann”). In this case, the system sees “space” as a delimiter. Instead of GTS-specific parameters, SAP HANA Search relies on internal delimiter handling in SAP HANA. However, even here, you can change the default delimiters used by HANA Search by changing the full-text index of SPL tables.
Standard SAP HANA Search delimiters are \/;,.:-_()[]<>!?*@+{}="&
Be aware that all characters are replaced by lowercase characters without any diacritics before the comparison takes place. This is called standardization. Therefore, it is possible to get a 100% match when comparing two unequal terms, because the standardization process returned two identical terms.
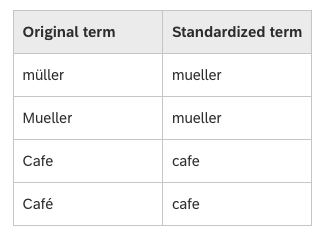
Details on how SAP HANA Search standardize letters can be found here:
https://help.sap.com/docs/SAP_HANA_PLATFORM/691cb949c1034198800afde3e5be6570/ce6c4480bb571014a44fdf7...
In classic GTS Search or TREX, the configuration for a minimum length of comparison terms is defined at the list type level. However, since the generation of search terms is no longer needed with SAP HANA Search, these parameters are no longer in effect when SAP HANA Search is used. The “missing” minimum length is fully compensated through other SAP HANA Search capabilities, such as stopwords and term mappings.
In some cases, minimum length produces undesirable results, since a minimum length of 3 characters would completely wipe out SPL hits on Business Partners like «KA PA SA». A Business Partner like «BM HOLDING SA» would be reduced to «HOLDING», producing no meaningful result. Short words are better handled with stopwords since the short words are not entirely neglected.
SAP HANA Search handles the defined Exclusion Texts (words) differently. TREX and GTS Search ignore these words completely. In SAP HANA Search, exclusion words are called stopwords. Stopwords are terms that are less significant for a search, for instance, abbreviations such as Ltd, AG, SE etc. Search is carried out as though the stopwords did not exist (either in the business partner or the SPL entry). However, stopwords influence the calculated fuzzy core. For example, an SPL entry with stopwords identical to the Business Partner record gets a higher score than one with differing or missing stopwords.

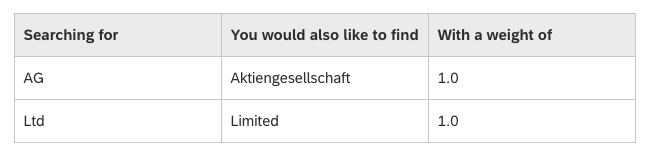
Term mappings can extend the search by adding additional search terms to the Business Partner record. Term Mappings will expand the search term, and synonyms, hypernyms, and hyponyms will be added. For instance, adding the complete form “Aktiengesellschaft” when the abbreviation AG is used or “United States” when “U.S.” is used. When stopwords and term mappings are combined in a single query, term mappings are applied first. Stopwords are then applied to all search term variations created by the term mappings.
For each comparison procedure, you can define four critical parameters. The parameters influence the outcome later presented as SPL hits. The first three parameters, all represented as percentages between 0 and 100, are:
Exactness
Percentage Rate of Matching Words
Minimum Score
In addition, there is a toggle selection called “Symmetric Search“.
Exactness represents the first stage in the screening process. Every word (referred to as tokens) in the Business Partner search string will receive an exactness score or a fuzzy score.
The fuzzy search algorithm calculates a fuzzy score for each string comparison. The higher the score, the more similar the strings are. A score of 1.0 means the strings are identical. A score of 0.0 means the strings have nothing in common.
Since most SPL-list contains several different spelling of the names for the same person or organization, you may be able to run with a higher exactness score than the results above could indicate.
Tokens (words) with a fuzzy score above the defined exactness level will be considered matching terms in the next stage of the screening process.
In the second stage, the system calculates the Percentage Rate of Matching Words. If the symmetric search is off, this will be the Percentage Rate of Matching Words of the Business Partner search string itself. If your symmetric search is on, the system uses both the business partner words and the sanctioned-party list words when calculating the matching percentage rate. This will produce two results, and the system will pick the one with the highest rate. On or off will therefore produce different results.
For example, if 2 out of three words in a Business Partner are defined as matching words, the PRMW is 66,7%. For a two-word search string with only one token qualifying as matching words, we are down to 50% PRMW. If the Percentage Rate of Matching Words parameter is set to 51%, the first example with three words will move to the next stage, whereas the last sample will be ignored and never appear as a potential hit. If the PRMW setting is 67%, all three words in a three-word-long search string must qualify as a match (according to the exactness parameter) to be eligible as a potential hit.
Please note that stopwords are excluded from the calculation of matching words.
The table below shows the number of words in a Business Partner that needs to qualify as matching words for it to qualify as a potential hit, with a varying percentage rate of matching words settings:
Percentage Potential Hit
50% 1 matching word out of 2 words
51%-66% 2 matching words out of 3 words
67%-75% 3 matching words out of 4 words
76%-80% 4 matching words out of 5 words.
Entries meeting the threshold for the Percentage Rate of Matching Words will enter stage 3. In Stage 3, SAP HANA Search determines a final score for each Business Partner search string. The token score above the exactness setting from the first stage will be used, influenced by the stopwords and term mapping.
Without stopwords and term mappings, this can be expressed as:
Final score = Square root(∑(tokenScore²) ÷ Maximum number of words in either BP name or SPL name).
Only Business Partners with a Final Score above the minimum score parameter will be presented as SPL hits, leading to blocked business partners and transactions.
Unlike the Exactness search parameter, this parameter affects the names and addresses as a whole and not the individual words.
You may, of course, wonder why you need to relate to all these parameters?
Ultimately, it is a balance between the required tolerance, your required security level and an acceptable workload. Tolerance may be needed due to data quality in your master data, maybe with considerable variations in spelling. If all your master data was written exactly like the entries in the SPL lists, no tolerance would be needed.
Depending on the sensitivity and risk in your industry, a higher and lower tolerance may be appropriate. High tolerance for errors will lead to more hits and, consequently, more false positives. Low tolerance may lead to desired SPL blocks not being implemented.
All hits, false or not, must be reviewed and require time and effort. So this is finally a question of the effort you want to invest in securing that you stay compliant.
To help you on the way, let us look at one example:
SPL Entry: MC OVERSEAS TRADING COMPANY SA DE CV
Exactness Score: 80%
Percentage Rate of Matching Words: 75%
Minimum Score: 70%
Stopwords: “SA”, and “SA DE CV”
The following Business Partners will be considered as hits (overall score):
MC OVERSEAS TRADING COMPANY DE CV SA (84%)
MC OVERSEAS TRADING COMPANY SA (99%)
MC OVERSEAS TRADING COMPANY SA DE (90%)
MC OVERSEAS TRADING COMPANY SB DE CV (75%)
AB OVERSEAS TRADING COMPANY SA DE CV (92%)
AB OVERSEAS TRADING COMPANY SA (88%)
AB OVERSEAS TRADING COMPANY (85%)
For the human eye, it may be obvious that the three last ones, should not be included.
Technically, they do, however, qualify.
Let´s adjust the parameters:
Exactness Score: 80%
Percentage Rate of Matching Words: 80%
Minimum Score: 70%
Stopwords: “SA”, and “SA DE CV”
MC OVERSEAS TRADING COMPANY DE CV SA (84%)
MC OVERSEAS TRADING COMPANY SA (99%)
MC OVERSEAS TRADING COMPANY SA DE (90%)
MC OVERSEAS TRADING COMPANY SB DE CV (75%)
AB OVERSEAS TRADING COMPANY SA DE CV no match
AB OVERSEAS TRADING COMPANY SA no match
AB OVERSEAS TRADING COMPANY no match
In our case, the many similar words obviously led to AB OVERSEAS TRADING COMPANY being considered a hit compared to MC OVERSEAS TRADING COMPANY.
When deciding the percentage rate of matching words, you should also consider whether the following names are matched names or not.
OVERSEAS TRADING COMPANY AB
OVERSEAS TRADING COMPANY XY
If these names are considered matching names, the percentage rate of matching words should be lower than or equal to 75%.
The higher the exactness score, the fewer tokens qualify as matching words. Therefore, a High exactness score setting will reduce the overall number of hits.
The higher the Percentage Rate of Matching Words parameters, the fewer Business Partners will appear as hits. Conversely, the lower it is set, the more false positives you should expect.
With a high minimum score set, the number of hits will be reduced. However, you will experience many false positives if it is too low.
Consider using symmetric search, in case the blocked BP name contains more words than the SPL name. Such as SPL name: ABC Nuclear Research Centre, and BP name: ABC Nuclear Research Centre OPQ XYZ.
If you want to learn more about SPL screening results in different comparison procedures, please check this out.
https://ga.support.sap.com/dtp/viewer/#/tree/2586/actions/35577
Recommended read for those looking for more details on SAP HANA search:
https://help.sap.com/docs/SAP_HANA_PLATFORM/691cb949c1034198800afde3e5be6570/ce86ef2fd97610149eaaaa0...
As GTS users are moving from TREX to SAP HANA Search, it is crucial to understand how the SAP HANA Search differs. If you apply the same parameter settings as with TREX, GTS will produce a different outcome, and you may therefore raise questions about its reliability. So, for starters, you should definitively not copy the parameter settings directly from TREX.
Delimiters
SAP HANA Search in GTS relies heavily on the search capabilities in the HANA database and not GTS-specific logic run on the application server. Consequently, SAP HANA Search does not utilize some of the parameters you traditionally define in SAP GTS, such as, for instance, the delimiters. Delimiters separate a search string into separate words or “tokens”. Delimiters ensure that a Business Partner entry like “Erika Mustermann” is handled as two different search terms (“Erika” and “Mustermann”) and not as one search term (“Erika Mustermann”). In this case, the system sees “space” as a delimiter. Instead of GTS-specific parameters, SAP HANA Search relies on internal delimiter handling in SAP HANA. However, even here, you can change the default delimiters used by HANA Search by changing the full-text index of SPL tables.
Standard SAP HANA Search delimiters are \/;,.:-_()[]<>!?*@+{}="&
Standardization of Letters and Terms
Be aware that all characters are replaced by lowercase characters without any diacritics before the comparison takes place. This is called standardization. Therefore, it is possible to get a 100% match when comparing two unequal terms, because the standardization process returned two identical terms.
Details on how SAP HANA Search standardize letters can be found here:
https://help.sap.com/docs/SAP_HANA_PLATFORM/691cb949c1034198800afde3e5be6570/ce6c4480bb571014a44fdf7...
Minimum Length
In classic GTS Search or TREX, the configuration for a minimum length of comparison terms is defined at the list type level. However, since the generation of search terms is no longer needed with SAP HANA Search, these parameters are no longer in effect when SAP HANA Search is used. The “missing” minimum length is fully compensated through other SAP HANA Search capabilities, such as stopwords and term mappings.
In some cases, minimum length produces undesirable results, since a minimum length of 3 characters would completely wipe out SPL hits on Business Partners like «KA PA SA». A Business Partner like «BM HOLDING SA» would be reduced to «HOLDING», producing no meaningful result. Short words are better handled with stopwords since the short words are not entirely neglected.
Stopwords
SAP HANA Search handles the defined Exclusion Texts (words) differently. TREX and GTS Search ignore these words completely. In SAP HANA Search, exclusion words are called stopwords. Stopwords are terms that are less significant for a search, for instance, abbreviations such as Ltd, AG, SE etc. Search is carried out as though the stopwords did not exist (either in the business partner or the SPL entry). However, stopwords influence the calculated fuzzy core. For example, an SPL entry with stopwords identical to the Business Partner record gets a higher score than one with differing or missing stopwords.
Term Mappings
Term mappings can extend the search by adding additional search terms to the Business Partner record. Term Mappings will expand the search term, and synonyms, hypernyms, and hyponyms will be added. For instance, adding the complete form “Aktiengesellschaft” when the abbreviation AG is used or “United States” when “U.S.” is used. When stopwords and term mappings are combined in a single query, term mappings are applied first. Stopwords are then applied to all search term variations created by the term mappings.
Search Parameters
For each comparison procedure, you can define four critical parameters. The parameters influence the outcome later presented as SPL hits. The first three parameters, all represented as percentages between 0 and 100, are:

Search Parameters
Exactness
Percentage Rate of Matching Words
Minimum Score
In addition, there is a toggle selection called “Symmetric Search“.

SAP HANA Search represented as Rocket Science
Exactness
Exactness represents the first stage in the screening process. Every word (referred to as tokens) in the Business Partner search string will receive an exactness score or a fuzzy score.
The fuzzy search algorithm calculates a fuzzy score for each string comparison. The higher the score, the more similar the strings are. A score of 1.0 means the strings are identical. A score of 0.0 means the strings have nothing in common.

Since most SPL-list contains several different spelling of the names for the same person or organization, you may be able to run with a higher exactness score than the results above could indicate.
Tokens (words) with a fuzzy score above the defined exactness level will be considered matching terms in the next stage of the screening process.
Percentage Rate of Matching Words
In the second stage, the system calculates the Percentage Rate of Matching Words. If the symmetric search is off, this will be the Percentage Rate of Matching Words of the Business Partner search string itself. If your symmetric search is on, the system uses both the business partner words and the sanctioned-party list words when calculating the matching percentage rate. This will produce two results, and the system will pick the one with the highest rate. On or off will therefore produce different results.
For example, if 2 out of three words in a Business Partner are defined as matching words, the PRMW is 66,7%. For a two-word search string with only one token qualifying as matching words, we are down to 50% PRMW. If the Percentage Rate of Matching Words parameter is set to 51%, the first example with three words will move to the next stage, whereas the last sample will be ignored and never appear as a potential hit. If the PRMW setting is 67%, all three words in a three-word-long search string must qualify as a match (according to the exactness parameter) to be eligible as a potential hit.
Please note that stopwords are excluded from the calculation of matching words.
The table below shows the number of words in a Business Partner that needs to qualify as matching words for it to qualify as a potential hit, with a varying percentage rate of matching words settings:
Percentage Potential Hit
50% 1 matching word out of 2 words
51%-66% 2 matching words out of 3 words
67%-75% 3 matching words out of 4 words
76%-80% 4 matching words out of 5 words.
Minimum score
Entries meeting the threshold for the Percentage Rate of Matching Words will enter stage 3. In Stage 3, SAP HANA Search determines a final score for each Business Partner search string. The token score above the exactness setting from the first stage will be used, influenced by the stopwords and term mapping.
Without stopwords and term mappings, this can be expressed as:
Final score = Square root(∑(tokenScore²) ÷ Maximum number of words in either BP name or SPL name).
Only Business Partners with a Final Score above the minimum score parameter will be presented as SPL hits, leading to blocked business partners and transactions.
Unlike the Exactness search parameter, this parameter affects the names and addresses as a whole and not the individual words.
Summary
You may, of course, wonder why you need to relate to all these parameters?
Ultimately, it is a balance between the required tolerance, your required security level and an acceptable workload. Tolerance may be needed due to data quality in your master data, maybe with considerable variations in spelling. If all your master data was written exactly like the entries in the SPL lists, no tolerance would be needed.
Depending on the sensitivity and risk in your industry, a higher and lower tolerance may be appropriate. High tolerance for errors will lead to more hits and, consequently, more false positives. Low tolerance may lead to desired SPL blocks not being implemented.
All hits, false or not, must be reviewed and require time and effort. So this is finally a question of the effort you want to invest in securing that you stay compliant.
To help you on the way, let us look at one example:
SPL Entry: MC OVERSEAS TRADING COMPANY SA DE CV
Exactness Score: 80%
Percentage Rate of Matching Words: 75%
Minimum Score: 70%
Stopwords: “SA”, and “SA DE CV”
The following Business Partners will be considered as hits (overall score):
MC OVERSEAS TRADING COMPANY DE CV SA (84%)
MC OVERSEAS TRADING COMPANY SA (99%)
MC OVERSEAS TRADING COMPANY SA DE (90%)
MC OVERSEAS TRADING COMPANY SB DE CV (75%)
AB OVERSEAS TRADING COMPANY SA DE CV (92%)
AB OVERSEAS TRADING COMPANY SA (88%)
AB OVERSEAS TRADING COMPANY (85%)
For the human eye, it may be obvious that the three last ones, should not be included.
Technically, they do, however, qualify.
Let´s adjust the parameters:
Exactness Score: 80%
Percentage Rate of Matching Words: 80%
Minimum Score: 70%
Stopwords: “SA”, and “SA DE CV”
MC OVERSEAS TRADING COMPANY DE CV SA (84%)
MC OVERSEAS TRADING COMPANY SA (99%)
MC OVERSEAS TRADING COMPANY SA DE (90%)
MC OVERSEAS TRADING COMPANY SB DE CV (75%)
AB OVERSEAS TRADING COMPANY SA DE CV no match
AB OVERSEAS TRADING COMPANY SA no match
AB OVERSEAS TRADING COMPANY no match
In our case, the many similar words obviously led to AB OVERSEAS TRADING COMPANY being considered a hit compared to MC OVERSEAS TRADING COMPANY.
When deciding the percentage rate of matching words, you should also consider whether the following names are matched names or not.
OVERSEAS TRADING COMPANY AB
OVERSEAS TRADING COMPANY XY
If these names are considered matching names, the percentage rate of matching words should be lower than or equal to 75%.
Conclusion
The higher the exactness score, the fewer tokens qualify as matching words. Therefore, a High exactness score setting will reduce the overall number of hits.
The higher the Percentage Rate of Matching Words parameters, the fewer Business Partners will appear as hits. Conversely, the lower it is set, the more false positives you should expect.
With a high minimum score set, the number of hits will be reduced. However, you will experience many false positives if it is too low.
Consider using symmetric search, in case the blocked BP name contains more words than the SPL name. Such as SPL name: ABC Nuclear Research Centre, and BP name: ABC Nuclear Research Centre OPQ XYZ.
Additional learning
If you want to learn more about SPL screening results in different comparison procedures, please check this out.
https://ga.support.sap.com/dtp/viewer/#/tree/2586/actions/35577
Recommended read for those looking for more details on SAP HANA search:
https://help.sap.com/docs/SAP_HANA_PLATFORM/691cb949c1034198800afde3e5be6570/ce86ef2fd97610149eaaaa0...
- SAP Managed Tags:
- SAP Global Trade Services
Labels:
4 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
Business Trends
145 -
Business Trends
15 -
Event Information
35 -
Event Information
9 -
Expert Insights
8 -
Expert Insights
29 -
Life at SAP
48 -
Product Updates
521 -
Product Updates
63 -
Technology Updates
196 -
Technology Updates
10
Related Content
- The Where, the Who, the What, and the Why of Trade Compliance and How Different SAP Solutions Keep Your Company Safe in Financial Management Blogs by SAP
- GRC Tuesdays: Hidden Gems – SAP Watch List Screening for Simplified Due Diligence and Compliance in Financial Management Blogs by SAP
- GLOBAL TRADE SERVICE - DENIED PARTY SCREENING STATUS UPDATED IN SAP S4 in Financial Management Q&A
- Embargo Check in SAP Global Trade Services, edition for SAP HANA in Financial Management Blogs by SAP
- 12 Good Reasons to Move to SAP GTS, edition for SAP HANA in Financial Management Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 2 | |
| 2 | |
| 2 | |
| 1 | |
| 1 | |
| 1 |