- SAP Community
- Products and Technology
- Technology
- Technology Q&A
- How to create a CUBE Calculation View without appl...
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
How to create a CUBE Calculation View without applying any aggregation to any measure column ?
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
on 11-22-2018 7:27 AM
Hi,
I have a CUBE type calculation view which I want to expose to SAP Analytics Cloud platform. I have a measure column INFLUENCE in the view for which I do not want to apply any aggregation. If I un-select the aggregation from the drop down , it automatically converts the column into attribute type. I want the column to remain as measure type but also not apply any aggregation on it.
The reason I am doing this is because in SAC I need to plot a chart which only works with measures vs attributes. Therefore I cannot allow the measure type to turn into attribute type.
Regards,
Dev
EDIT : --------
1. This is the calculation view columns. I want to set the INFLUENCE column to measure (which it already is ) but remove the SUM aggregation from it. Currently, if i remove the SUM aggregation, the column INFLUENCE automatically reverts to attribute type.

2. This is the data from the original calculation view where all the columns including the INFLUENCE column is of attribute type. Unfortunately, such type of calculation view (dimension) cannot be consumed in SAC. As a result, I had to refactor the dimension type Calculation view to Cube type calculation view by just adding a AGGREGATE node at the top.

As you can see for CUST_ID= 200002710 , there are 2 separate entries.
3. This is the data that I receive after building the calculation view (1) is as follows :-
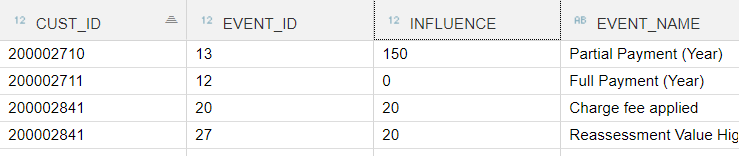
As you can see for CUST_ID=200002710, the INFLUENCE column seems to have changed with a summation value. How is it 150, I have no idea. It should be 40 ideally. But keeping that aside for a moment, is it possible to change the INFLUENCE type aggregation to NONE and yet retain it as measure type (as it is required to be measure type for plotting in a chart in SAC ) ??
{kind=link}
{kind=link}
{kind=link}
- SAP Managed Tags:
- SAP Analytics Cloud,
- SAP HANA
Accepted Solutions (1)
Accepted Solutions (1)
- Mark as New
- Bookmark
- Subscribe
- Subscribe to RSS Feed
- Report Inappropriate Content
When you are using CUBE type of calculation view, records will be always aggregated (dimensions will be grouped together and on measure provided aggregation function -Min/Max/Sum etc. will be applied).
To prevent aggregation you need to return unique key for each record (if it's available in your datasource). If in your source data there is no unique key identifier, you can try to generate artificial key using Rank node. Then you would also need to return that key in the output.
Here is an example:
![]()
Then in output you will have unique combination of records so data are not aggregated:

Not sure if in your scenario this solution helps, but I don't see any other option if you are using Native HANA and the INFLUENCE column needs to remain of a measure type.
In SAP BW you could define non-cumulative key figure, but I assume that you are not using BW.
{kind=link}
{kind=link}
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
- Mark as New
- Bookmark
- Subscribe
- Subscribe to RSS Feed
- Report Inappropriate Content
Hi,
So I followed your solution but I am receiving the following error while I try to preview the data. The build process takes place successfully.

The Rank node's configuration is as follows -

I have given the threshold as 214992 because I have that many entries in the Calculation view.
I have tried to build the View with a lower threshold (5) and I could see the Data preview. In that case the rank_column consisted of values ranging from 1-15 which is weird because I have specified threshold=5. Needless to say, the rank values were repeated many times.
Also note that my CUST_ID column contains some duplicate values too. But if I understand corectly, Rank node is supposed to generate a count from 1- 214992 without containing any duplicates regardless of the CUST_ID value. Keeping that in mind, I have tried to include all the columns in the PARTITION BY clause - CUST_ID, EVENT_ID, INFLUENCE etc. This too resulted in the same error as above. This seems to me that Threshold value cannot be more than a specified range.
Regards,
Dev.
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Subscribe to RSS Feed
- Report Inappropriate Content
Hi,
So I tried something different from what you suggested. I created a DUMMY column with all values=1. Then passed the projection to a RANK node with following config:

The Rank node will now create rank on the DUMMY column. 214992 ---> because I have that many values in my Calculation view.
But unlike your solution, where you specified to AGGREGATE columns ---> INFLUENCE and RANK_Column in the Aggregation node. I have just aggregated INFLUENCE column and kept the Rank_column as attribute.

This seem to have worked. I have no idea why. Because if this works, then my initial Calculation view should have worked too. My initial Calculation view didn't contain the Rank_Column but there I had the aggregation on only the INFLUENCE column too. So, just like here, even in the initial Calculation view it should not have aggregated the INFLUENCE column. This is a very weird behavior.
My initial Calculation view looked something like this :

If you notice, both the Calculation views are similar when it comes to aggregation column, yet one works and another doesn't.
Also, regarding my previous comment to your answer, I believe when I aggregate as follows (specified by you), due to presence of repeated values in INFLUENCE column, it tries to add them up but the resulting value is too big to be of type INTEGER type and hence the error. I could be wrong . Really appreciate if you could clear this up for me.

Your idea to use RANK node led me to my solution so I am accepting your answer. Thank you very much for that. But I would love to still hear your opinion on why it works now.
Regards,
Dev
Answers (0)
- SAP HANA Cloud's Vector Engine vs. HANA on-premise in Technology Blogs by Members
- SAP Analytics Cloud - %Subtotal in Hierarchies in Technology Q&A
- SAP Analytics Cloud Planning - Converting data in Technology Blogs by SAP
- SAC - Add Row total to Dimension Subtotal? in Technology Q&A
- SAP HANA Calculation view. Incorrect Count in Technology Q&A
| User | Count |
|---|---|
| 87 | |
| 10 | |
| 10 | |
| 9 | |
| 7 | |
| 7 | |
| 6 | |
| 5 | |
| 4 | |
| 4 |
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.