- SAP Community
- Products and Technology
- Technology
- Technology Q&A
- Smart Data Streaming to Hadoop - Nothing appears i...
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
Smart Data Streaming to Hadoop - Nothing appears in Hadoop
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
on 03-27-2017 2:36 PM
I am trying to stream out some test data from Smart Data Streaming to Hadoop with "File/Hadoop CSV Output Adapter", but no file or data appears in HDFS despite no error message appearing in the SDS project.
THE PART THAT FEELS CORRECT
With the same type of stream project I have already succeeded in outputting to local server. And my Hadoop is working, I can upload csv files to hdfs manually.
I have tried to follow the SDS documentation (https://help.sap.com/viewer/c490089d7b0a4db5b5ea19f1f2f1b4fd/1.0.11/en-US/c33bcb83bf5a4155bcbf68e3a19d76f8.html ) as close as possible, I have:
- Copied the necessary jar files from the Hadoop server over to $STREAMING_CUSTOM_ADAPTERS_HOME/libj on the SDS server.
- Filled in the compulsory properties fields dir and files
The guide did not tell me to configure environment variables, but since the guide refers to these in relation to filepaths, I think I have to set the variables, so I have configured them on my Smart Data Streaming server:
export STREAMING_CUSTOM_ADAPTERS_HOME=/hana/shared/HDB/streaming-1_00_120_00_160428/cluster/hdb/adapters
export STREAMING_HOME=/hana/shared/HDB/streaming-1_00_120_00_160428/STREAMING-1_0
export JAVA_HOME=$STREAMING_HOME/lib/jre
THE PART THAT FEELS WRONG
The file directory instruction in the documentation is ambiguous: "To use Hadoop system files, use an HDFS folder instead of a local file system folder. For example,hdfs://<hdfs-server>:9000/<folder-name><sub-folder-name>/<leaf-folder-name>."
What is the <hdfs-server>? Is it the IP of the Linux server my Hadoop is on, or is it the IP of HDFS? In Ambari, this info appears about my NameNode:

(I have used fake IP in this post),
However, the IP of my Linux server with Hadoop on is completely different.
In examples like this: https://wiki.scn.sap.com/wiki/display/SYBESP/Hadoop the server has alias name, not IP-address: dewdfglp01294.wdf.sap.corp. I don't think I have an alias name like that to use.
Another thing is that the guide tells me to use port 9000, however, in the core-site.xml file the port is set at 8020.
<name>fs.defaultFS</name>
<value>hdfs://ip-180-80-80-333.ec2.internal:8020</value>
<final>true</final>
Should I use 8020 for the adapter, or should I change the value in core-site.xml file to 9000?
My project looks like this:

Does it make a difference if the csv file already exists in this place or not?
I have experienced that HDFS files cannot be seen with FileZilla just connected to the Linux server with Hadoop on, but can be seen if going into "Browse the file system" on the Linux server's port 50070. However I cannot see the output file appearing here, and the project doesn't display any error message when outputting to Hadoop.
In case it's relevant, I installed Hadoop following this instruction: https://www.youtube.com/watch?v=MBvK7SzhA_E&list=PLkzo92owKnVySPBoRJHfqNOOTQrnMrja2#t=201.155148
Has anyone got an adapter from Smart Data Streaming to Hadoop working? If so, how have you solved it?
{kind=link}
{kind=link}
{kind=link}
- SAP Managed Tags:
- SAP HANA streaming analytics
Accepted Solutions (0)
Answers (4)
Answers (4)
- Mark as New
- Bookmark
- Subscribe
- Subscribe to RSS Feed
- Report Inappropriate Content
Hi Morten,
1. In you case the URI should be start with hdfs://ip-180-80-80-333.ec2.internal:8020/
HDFS adapter use this url to read/write files in HDFS.
2. One potential error for the no file created may be current user does not have permission to write to the folder/file on your hdfs system.
I suggest to set the folder mode to be 666 or 777 to allow all the user to write data to the test folder to have a try.
3. If no csv file exist, adapter will create a new file, and if the csv file already exists, adapter will try to overwrite it.
(User can append file with the parameter of appendFile, which by default is false)
4. If the issue still not resolved, as Robert mentioned, I suggest to paste the adapter log so that we can look more into the error.
Regards,
Ming
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
- Mark as New
- Bookmark
- Subscribe
- Subscribe to RSS Feed
- Report Inappropriate Content
Hi Ming,
Thank you for your help.
I had actually forgotten to change the permission to the user cluster_admin in hdfs, I had first just done it on HDFS' local Linux server. So I fixed this by adding: hdfs dfs -chmod 777 /user/cluster_admin
However, it still did not work.
I have tried URI hdfs://ip-180-80-80-333.ec2.internal:8020 as you recommended, and then the adapter state is "DEAD":

When trying with other URI variations like the following, the output adapter state is CONTINIOUS:
- hdfs://180.80.80.333:8020
- hdfs://180.80.80.333:9000
But still no file appearing in HDFS.
I will attach the log files so you can have a look at them (here to I have replaced the real IPs with 180.80.80.333 and the like to keep my system private): streamingserver-log.txt streamingserver-project-out.txt streamingserver-project-trc.txt
And I think I have the right jar files in right place copied from hdfs server to streaming server:
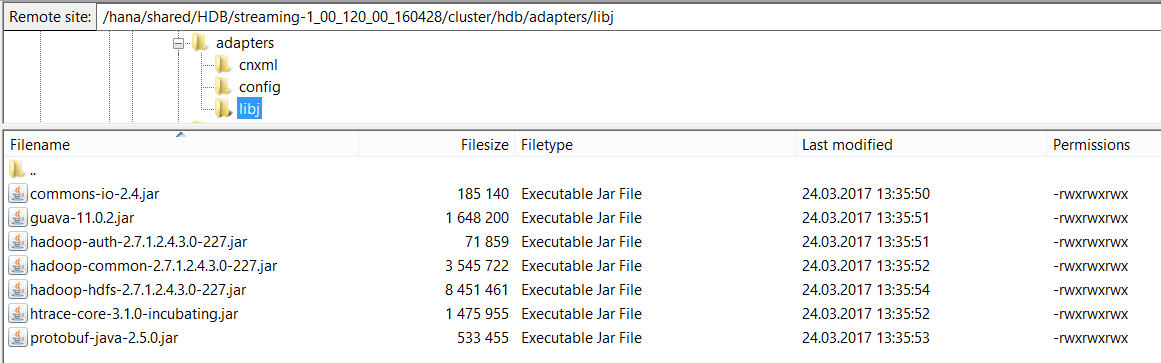
My ideas for why it is till not working:
- ip-180-80-80-333.ec2.internal is internal IP-address, in contrast to 180.80.80.333, so I cannot reach this from the external server where my Smart Data Streaming is. Hadoop and HDFS is of course on a different server than my Smart Data Streaming
- Is the port 9000 set some other places in my system, so that although the port in the core-site.xml file on the Hadoop server is set to 8020, other parts of my system, f.example on the streaming server expect this to be 9000?
- Are there some more environment variables I should set? On my streaming server I have already set:
export STREAMING_CUSTOM_ADAPTERS_HOME=/hana/shared/HDB/streaming-1_00_120_00_160428/cluster/hdb/adapters
export STREAMING_HOME=/hana/shared/HDB/streaming-1_00_120_00_160428/STREAMING-1_0
export JAVA_HOME=$STREAMING_HOME/lib/jre
- Or there could be so many other stuff not set properly...
{kind=link}
{kind=link}
- Mark as New
- Bookmark
- Subscribe
- Subscribe to RSS Feed
- Report Inappropriate Content
Hi Morten,
From the error log, it seems you should copy another two jar files together with the other hadoop jar files mentioned in my previous mail.
jackson-mapper-asl-1.9.13.jar
jackson-core-asl-1.9.13.jar
Although these two files are not required in my local test environment, it seems it is required by your environment.
These two jar files can also be found in apache hadoop 2.7.3 binary package.
Can you have a try to see if this can help to resolve the issue? Thanks.
Regards,
Ming
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
- Mark as New
- Bookmark
- Subscribe
- Subscribe to RSS Feed
- Report Inappropriate Content
Hi Ming,
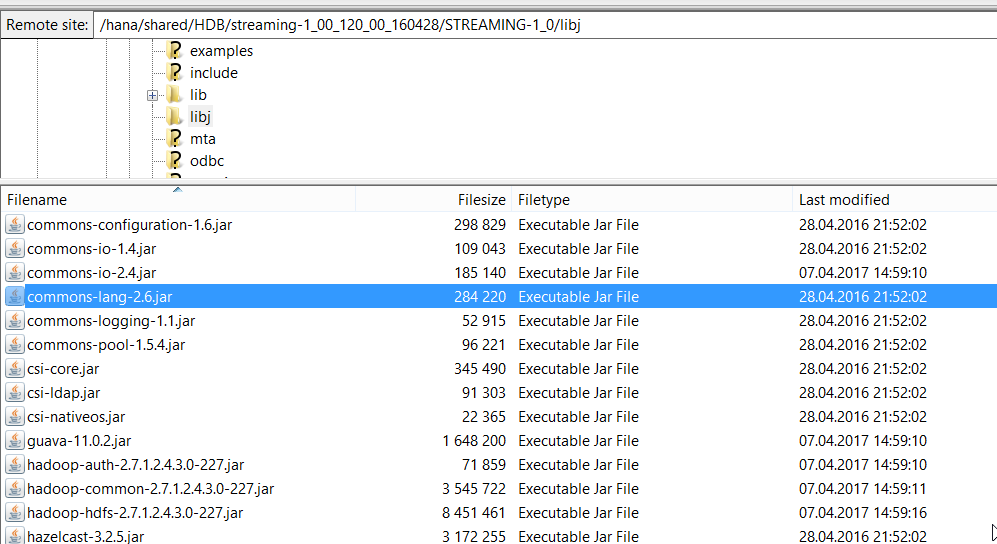
Thanks again, however, it still does not work. I do not understand how I could have done it differently, I have copied the jar files into the directory, and I have tried several different directories, as I am not completely sure which should be STREAMING_CUSTOM_ADAPTERS_HOME. I have tried 3 different places, and put the jar files in all of them
- export STREAMING_CUSTOM_ADAPTERS_HOME=/hana/shared/HDB/streaming-1_00_120_00_160428/STREAMING-1_0/adapters/framework/
- export STREAMING_CUSTOM_ADAPTERS_HOME=/hana/shared/HDB/streaming-1_00_120_00_160428/STREAMING-1_0
- export STREAMING_CUSTOM_ADAPTERS_HOME=/hana/shared/HDB/streaming-1_00_120_00_160428/cluster/hdb/adapters


{kind=link}
{kind=link}
{kind=link}
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
- Mark as New
- Bookmark
- Subscribe
- Subscribe to RSS Feed
- Report Inappropriate Content
Hi Morten,
The 3rd location is correct:
STREAMING_CUSTOM_ADAPTERS_HOME=/hana/shared/HDB/streaming-1_00_120_00_160428/cluster/hdb/adapters
Copying the custom jars to /hana/shared/HDB/streaming-1_00_120_00_160428/STREAMING-1_0/adapters/framework/libj will also work however they will not get preserved during an upgrade of SDS so it is better to copy them to
/hana/shared/HDB/streaming-1_00_120_00_160428/cluster/hdb/adapters/libj
By the way, for adapters that are run in managed and cluster-managed mode you should not have to manually set any environment variables as they will get set in the environment for the <sid>adm user.
Regards,
Gerald
- Mark as New
- Bookmark
- Subscribe
- Subscribe to RSS Feed
- Report Inappropriate Content
Hi Morten,
From the error log, the HDFS library jar files are not initialized successfully. Maybe it is due to the Hadoop jar files are not copied before the start of adapter. Please refer to this document
to copy these files over to $STREAMING_CUSTOM_ADAPTERS_HOME/libj and restart the adapter (with user <sid>adm):
- commons-io-2.4.jar
- guava-11.0.2.jar
- hadoop-auth-2.7.0.jar
- hadoop-common-2.7.0.jar
- hadoop-hdfs-2.7.0.jar
- htrace-core-3.1.0-incubating.jar
- protobuf-java-2.5.0.jar
Error logs:
03-31-2017 12:04:51.196 WARN [main] (FileSystem.loadFileSystems) Cannot load filesystem
java.util.ServiceConfigurationError: org.apache.hadoop.fs.FileSystem: Provider org.apache.hadoop.hdfs.web.WebHdfsFileSystem could not be instantiated
at java.util.ServiceLoader.fail(ServiceLoader.java:232)
at java.util.ServiceLoader.access$100(ServiceLoader.java:185)
at java.util.ServiceLoader$LazyIterator.nextService(ServiceLoader.java:384)
at java.util.ServiceLoader$LazyIterator.access$700(ServiceLoader.java:323)
at java.util.ServiceLoader$LazyIterator$2.run(ServiceLoader.java:407)
at java.security.AccessController.doPrivileged(Native Method)
at java.util.ServiceLoader$LazyIterator.next(ServiceLoader.java:409)
at java.util.ServiceLoader$1.next(ServiceLoader.java:480)
at org.apache.hadoop.fs.FileSystem.loadFileSystems(FileSystem.java:2684)
at org.apache.hadoop.fs.FileSystem.getFileSystemClass(FileSystem.java:2703)
at org.apache.hadoop.fs.FileSystem.createFileSystem(FileSystem.java:2720)
at org.apache.hadoop.fs.FileSystem.access$200(FileSystem.java:95)
at org.apache.hadoop.fs.FileSystem$Cache.getInternal(FileSystem.java:2756)
at org.apache.hadoop.fs.FileSystem$Cache.get(FileSystem.java:2738)
at org.apache.hadoop.fs.FileSystem.get(FileSystem.java:376)
at com.sybase.esp.adapter.transporters.file.out.DataSinkHDFSAccessory.sanityCheck(DataSinkHDFSAccessory.java:33)
at com.sybase.esp.adapter.transporters.file.FileOutputTransporter.init(FileOutputTransporter.java:483)
at com.sybase.esp.adapter.framework.wrappers.TransporterWrapper.init(TransporterWrapper.java:61)
at com.sybase.esp.adapter.framework.internal.Adapter.init(Adapter.java:216)
at com.sybase.esp.adapter.framework.internal.AdapterController.executeStart(AdapterController.java:256)
at com.sybase.esp.adapter.framework.internal.AdapterController.execute(AdapterController.java:155)
at com.sybase.esp.adapter.framework.Framework.main(Framework.java:62)
Caused by: java.lang.NoClassDefFoundError: org/codehaus/jackson/map/ObjectMapper
at org.apache.hadoop.hdfs.web.WebHdfsFileSystem.<clinit>(WebHdfsFileSystem.java:142)
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:408)
at java.lang.Class.newInstance(Class.java:438)
at java.util.ServiceLoader$LazyIterator.nextService(ServiceLoader.java:380)
... 19 more
Caused by: java.lang.ClassNotFoundException: org.codehaus.jackson.map.ObjectMapper
at java.net.URLClassLoader$1.run(URLClassLoader.java:435)
at java.net.URLClassLoader$1.run(URLClassLoader.java:424)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:423)
at java.lang.ClassLoader.loadClass(ClassLoader.java:493)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:351)
at java.lang.ClassLoader.loadClass(ClassLoader.java:426)
... 26 more
03-31-2017 12:04:51.200 WARN [main] (FileSystem.loadFileSystems) Cannot load filesystem
java.util.ServiceConfigurationError: org.apache.hadoop.fs.FileSystem: Provider org.apache.hadoop.hdfs.web.SWebHdfsFileSystem could not be instantiated
at java.util.ServiceLoader.fail(ServiceLoader.java:232)
at java.util.ServiceLoader.access$100(ServiceLoader.java:185)
at java.util.ServiceLoader$LazyIterator.nextService(ServiceLoader.java:384)
at java.util.ServiceLoader$LazyIterator.access$700(ServiceLoader.java:323)
at java.util.ServiceLoader$LazyIterator$2.run(ServiceLoader.java:407)
at java.security.AccessController.doPrivileged(Native Method)
at java.util.ServiceLoader$LazyIterator.next(ServiceLoader.java:409)
at java.util.ServiceLoader$1.next(ServiceLoader.java:480)
at org.apache.hadoop.fs.FileSystem.loadFileSystems(FileSystem.java:2684)
at org.apache.hadoop.fs.FileSystem.getFileSystemClass(FileSystem.java:2703)
at org.apache.hadoop.fs.FileSystem.createFileSystem(FileSystem.java:2720)
at org.apache.hadoop.fs.FileSystem.access$200(FileSystem.java:95)
at org.apache.hadoop.fs.FileSystem$Cache.getInternal(FileSystem.java:2756)
at org.apache.hadoop.fs.FileSystem$Cache.get(FileSystem.java:2738)
at org.apache.hadoop.fs.FileSystem.get(FileSystem.java:376)
at com.sybase.esp.adapter.transporters.file.out.DataSinkHDFSAccessory.sanityCheck(DataSinkHDFSAccessory.java:33)
at com.sybase.esp.adapter.transporters.file.FileOutputTransporter.init(FileOutputTransporter.java:483)
at com.sybase.esp.adapter.framework.wrappers.TransporterWrapper.init(TransporterWrapper.java:61)
at com.sybase.esp.adapter.framework.internal.Adapter.init(Adapter.java:216)
at com.sybase.esp.adapter.framework.internal.AdapterController.executeStart(AdapterController.java:256)
at com.sybase.esp.adapter.framework.internal.AdapterController.execute(AdapterController.java:155)
at com.sybase.esp.adapter.framework.Framework.main(Framework.java:62)
Ming
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
- Mark as New
- Bookmark
- Subscribe
- Subscribe to RSS Feed
- Report Inappropriate Content
Hi Ming,
I left my answer to this answer from you as a comment on my original question, so please check there.
As you see I am a bit unsure what are the correct environment variables, and where to put the jar files, but I have tried different places.
However, I realised that I hadn't followed this instruction to start the adapter after configuring it.
I think I am in Managed mode, so I followed the instructions for that, but failed on this:
$STREAMING_HOME/bin/streamingcompiler -i hanasds_kystv_01_hadooptest.ccl -o hanasds_kystv_01_hadooptest.ccx
Because my project hanasds_kystv_01_hadooptest.cc is of course unfamiliar for the server as the workspace is on my local computer.... Am I supposed to have the project on the Smart Data Streaming server before running it?
- Mark as New
- Bookmark
- Subscribe
- Subscribe to RSS Feed
- Report Inappropriate Content
If you are deploying your project to the streaming server from Studio, you do not need to perform steps b), c), and d) in the documentation.
Have you made any changes to
/hana/shared/HDB/streaming-1_00_120_00_160428/STREAMING-1_0/adapters/framework/instances/file_csv_output/adapter_config.xml ?
In regards to the environment variable and jar location, please see my other comment.
Regards,
Gerald
- Import Data Connection to SAP S/4HANA in SAP Analytics Cloud : Technical Configuration in Technology Blogs by Members
- The Session Timer only appears after the first inactivity. in Technology Q&A
- Header Facet is displayed as a section facet in edit/create mode in Technology Q&A
- Enabling SAML Single Sign-On for SAP S/4 HANA and SAP BTP Apps using the same SAP IDP in Technology Blogs by SAP
- Configuring SAP CI/CD pipeline for Deploying ReactJS application in Cloud Foundry in Technology Blogs by Members
| User | Count |
|---|---|
| 75 | |
| 9 | |
| 8 | |
| 7 | |
| 7 | |
| 6 | |
| 6 | |
| 6 | |
| 5 | |
| 4 |
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.